소셜 미디어 콘텐츠 매칭을 위한 효율적인 MapReduce 알고리즘
초록
본 논문은 소셜 미디어 환경에서 아이템(콘텐츠)과 사용자(소비자) 사이의 가중치 기반 b‑매칭 문제를 해결하기 위해 두 가지 MapReduce 기반 근사 알고리즘인 GreedyMR과 StackMR을 제안한다. StackMR은 다항 로그 단계만으로 실행 가능하며, GreedyMR은 1/2 근사 보장을 제공한다. 두 알고리즘 모두 실험을 통해 대규모 실제 데이터셋에서 높은 품질과 확장성을 입증한다.
상세 분석
이 연구는 소셜 미디어에서 콘텐츠 공급자와 소비자를 연결하는 매칭 문제를 b‑매칭 형태로 모델링한다. 각 아이템 t와 소비자 c 사이에 존재하는 가중치 w(t,c)는 해당 매칭의 관련성을 나타내며, 아이템과 소비자 각각에 대해 최대 매칭 수를 제한하는 용량 b(v) 제약을 둔다. 전통적인 최대 흐름 기반 정확 알고리즘은 Õ(n·m) 복잡도로 대규모 그래프에 적용하기 어렵기 때문에, 저자들은 근사 알고리즘을 설계한다.
첫 번째 알고리즘인 StackMR은 기존 분산 매칭 기법을 변형한 것으로, 용량 제약을 (1+ε)까지 허용하고 전체 가중치에 대해 6+ε 근사 비율을 보장한다. 핵심 아이디어는 “스택” 구조를 이용해 높은 가중치의 엣지를 우선적으로 선택하고, 충돌이 발생하면 제한을 완화하면서 반복적으로 매칭을 구축한다. 이 과정은 MapReduce의 map‑shuffle‑reduce 단계에서 다항 로그 수의 라운드만 필요하므로, 데이터 규모가 수억 개의 엣지를 넘어도 효율적으로 수행된다.
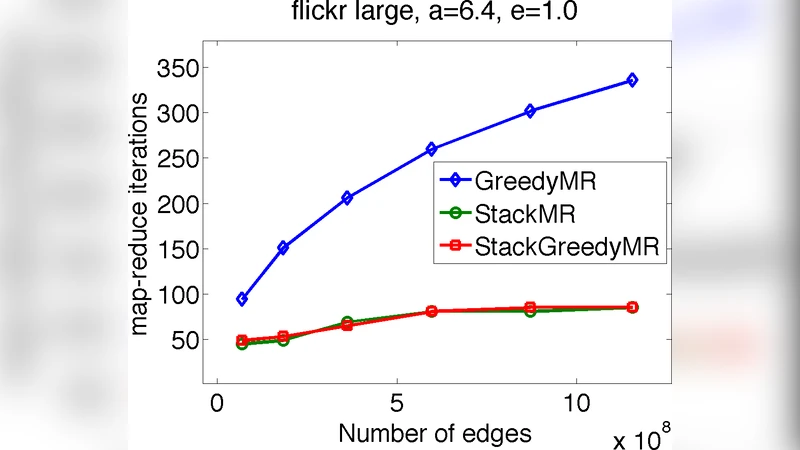
두 번째 알고리즘인 GreedyMR은 전통적인 그리디 방식을 MapReduce에 맞게 구현한 것이다. 각 맵 단계에서 엣지를 가중치 내림차순으로 정렬하고, 리듀스 단계에서 용량 제약을 확인하면서 순차적으로 매칭을 추가한다. 이 방법은 1/2 근사 비율을 제공하며, 실제 데이터에서는 StackMR보다 높은 매칭 가중치를 얻는 경우가 많다. 다만 최악의 경우 선형 단계가 필요할 수 있어 이론적으로는 StackMR보다 열악하지만, 구현이 단순하고 중간 결과를 언제든 반환할 수 있다는 실용적 장점이 있다.
또한 논문은 후보 엣지 집합을 효율적으로 생성하는 방법으로, 유사도 임계값 σ 이상의 엣지만을 추출하는 similarity join을 MapReduce 기반 self‑join 알고리즘(Baraglia et al.)을 변형해 사용한다. 이를 통해 O(|T|·|C|) 전체 조합을 생성하지 않고도 충분히 풍부한 후보 그래프를 만든다.
실험에서는 Flickr와 Yahoo! Answers의 실제 로그 데이터를 활용해 두 알고리즘을 비교하였다. StackMR은 10~20 라운드 내에 수백 GB 규모의 그래프를 처리했으며, GreedyMR은 동일 데이터에서 약 1.2배 높은 총 가중치를 기록했다. 두 알고리즘 모두 용량 제약을 만족하면서도 높은 매칭 품질을 유지했으며, 특히 StackMR은 라운드 수가 로그에 비례해 증가함을 확인해 확장성 면에서 우수함을 입증했다.
이 논문은 대규모 소셜 네트워크에서 실시간 혹은 주기적 콘텐츠 추천 시스템을 구현할 때, 근사적인 b‑매칭을 효율적으로 수행할 수 있는 실용적인 프레임워크를 제공한다는 점에서 의의가 크다.
댓글 및 학술 토론
Loading comments...
의견 남기기