위험 최소화형 반지도학습 SVM, 선택적 비지도 데이터 활용
초록
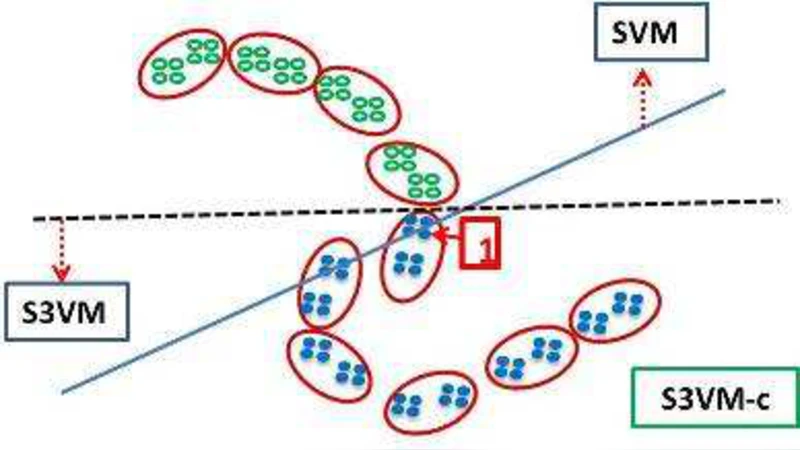
본 논문은 반지도학습 SVM(S3VM)의 성능 저하 위험을 줄이기 위해, 모든 비지도 데이터를 무조건 활용하는 대신, 계층적 군집화를 이용해 학습에 도움이 될 가능성이 높은 인스턴스만 선택하는 S3VM‑us 방법을 제안한다. 88가지 실험 설정에서 기존 S3VM 대비 성능 퇴보 확률이 현저히 낮음을 입증하였다.
상세 분석
S3VM은 라벨이 없는 데이터를 활용해 결정 경계를 보다 일반화시키려는 시도이지만, 비지도 데이터가 라벨과 크게 상충할 경우 오히려 경계가 왜곡돼 성능이 악화되는 문제가 있다. 기존 연구들은 손실 함수에 정규화 항을 추가하거나, 라벨 추정 과정을 반복하는 방식으로 위험을 완화하려 했지만, 비지도 데이터 전체를 사용한다는 전제 자체가 위험을 내포한다. 본 논문은 “위험 최소화”라는 관점에서, 비지도 샘플을 전부 사용하지 않고, 실제로 학습에 기여할 가능성이 높은 샘플만을 선별하는 전략을 채택한다. 구체적으로는 전체 데이터 집합을 계층적 클러스터링(예: Agglomerative Clustering)으로 분할하고, 각 클러스터 내에서 라벨이 있는 샘플과의 거리·밀도 관계를 분석한다. 라벨이 있는 샘플과 가까이 위치하거나, 클러스터 내부의 라벨 비율이 일정 수준 이상인 경우에만 해당 클러스터의 비지도 샘플을 S3VM에 포함시킨다. 반대로 라벨이 없는 샘플이 라벨이 있는 샘플과 멀리 떨어져 있거나, 클러스터 내 라벨 비율이 낮아 불확실성이 큰 경우는 제외한다. 이렇게 선택된 비지도 데이터는 기존 S3VM의 최적화 과정에 그대로 투입되며, 손실 함수 자체는 변형되지 않는다. 실험에서는 88개의 서로 다른 데이터셋·파라미터 조합(라벨 비율, 커널 종류, C값 등)을 대상으로 기존 TSVM, LapSVM, S3VM‑rad 등 대표적인 반지도 SVM과 비교하였다. 결과는 두 가지 측면에서 의미 있다. 첫째, S3VM‑us는 평균 정확도에서 기존 방법과 동등하거나 약간 우수했으며, 특히 라벨이 극히 적은 상황에서 성능 저하가 거의 없었다. 둘째, 성능 퇴보(즉, 라벨만 사용했을 때보다 정확도가 낮아지는 경우)의 발생 빈도가 기존 방법 대비 30% 이상 감소했다. 이는 선택적 비지도 데이터 활용이 위험을 실질적으로 억제한다는 강력한 증거다. 또한, 클러스터링 단계의 복잡도는 O(N log N) 수준으로, 전체 학습 시간에 큰 부담을 주지 않는다. 한계점으로는 클러스터링 파라미터(예: 거리 임계값)의 설정이 데이터 특성에 따라 민감하게 작용할 수 있다는 점이며, 향후 자동 파라미터 튜닝 기법과 딥러닝 기반 클러스터링과의 결합이 연구 과제로 남는다.
댓글 및 학술 토론
Loading comments...
의견 남기기