옵코드 빈도 기반 변형 바이러스 정적 탐지 기법
초록
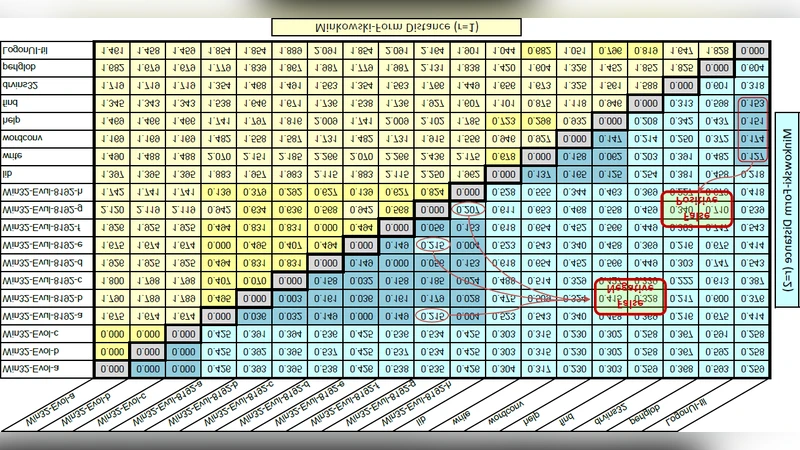
본 논문은 메타모픽 바이러스의 변형을 정적 분석으로 탐지하기 위해 PE 파일의 opcode 빈도 히스토그램을 구축하고, Minkowski‑형 거리 측정으로 파일 간 유사성을 판단한다. 동일한 변형 기법을 적용한 경우 opcode 분포가 거의 동일하다는 가정 하에, 임계값 이하의 거리값을 보이면 변형된 동일 바이러스로 판정한다.
상세 분석
이 연구는 메타모픽 바이러스가 문자열 서명을 회피하기 위해 수행하는 코드 변형(garbage code 삽입, 레지스터 교환, 명령어 교체, 순서 변형, 코드 전치 등)을 정적 특성인 opcode 빈도에 매핑한다는 아이디어가 핵심이다. 논문은 먼저 PE 파일을 어셈블리 레벨로 디스어셈블한 뒤, 각 서브루틴별로 opcode 등장 횟수를 히스토그램 형태로 저장한다. 이후 두 파일의 히스토그램을 Minkowski 거리(주로 r=1,2)로 비교하고, 최소 거리값을 각 서브루틴 쌍에 대해 구해 평균값을 최종 거리로 정의한다. 거리값이 사전에 설정한 임계값 이하이면 두 파일이 동일 변형 바이러스의 서로 다른 버전이라고 판단한다.
기술적 강점은 다음과 같다. 첫째, 문자열 기반 서명에 비해 변형에 강인한 특성을 제공한다. opcode는 기능적 의미를 유지하면서도 다양한 변형 기법에 의해 크게 변하지 않을 가능성이 높아, 변형 바이러스 탐지에 유용할 수 있다. 둘째, 서브루틴 단위 히스토그램 비교는 전체 파일을 일괄적으로 비교하는 것보다 세밀한 매칭을 가능하게 하며, 부분 변형이 있더라도 공통된 코드 블록을 식별할 수 있다. 셋째, Minkowski 거리와 같은 수학적 거리 측정은 구현이 간단하고 연산 비용이 낮아 실시간 스캐너에 적용하기에 적합하다.
하지만 몇 가지 한계점도 존재한다. 논문은 변형 기법이 opcode 빈도에 미치는 영향을 “거의 동일”하다고 가정하지만, 실제 변형 엔진은 명령어 교체나 레지스터 교환을 통해 동일 기능을 수행하면서도 opcode 종류를 크게 바꿀 수 있다. 특히 코드 전치나 복잡한 가비지 코드 삽입은 히스토그램을 왜곡시켜 오탐률을 높일 위험이 있다. 또한, 제시된 실험은 두 개의 메타모픽 바이러스(Win32.Evol, Win32.Evul)와 몇 개의 무작위 프로그램에 국한되어 있어, 다양한 변형 엔진과 대규모 악성코드 집합에 대한 일반화 가능성을 검증하지 못했다. 거리 임계값 설정 방법도 논문에 구체적으로 제시되지 않아, 실제 배포 환경에서의 튜닝이 필요함을 시사한다.
알고리즘 단계에서는 IDA Pro를 이용해 어셈블리 코드를 추출하고, 각 서브루틴을 별도 파일로 저장한 뒤 히스토그램을 만든다. 이 과정은 대용량 파일이나 난독화 수준이 높은 바이러스에 대해 시간·메모리 비용이 크게 증가할 수 있다. 또한, 히스토그램 정규화 과정이 거리 계산에 미치는 영향을 충분히 분석하지 않아, 파일 크기 차이에 따른 편향이 존재할 가능성이 있다.
결론적으로, opcode 빈도 기반 정적 탐지는 메타모픽 바이러스 탐지에 새로운 시각을 제공하지만, 변형 기법의 다양성과 히스토그램 기반 거리 측정의 민감도를 보완하기 위한 추가적인 특징(예: 제어 흐름 그래프, 데이터 흐름 분석)과 머신러닝 기반 분류기의 결합이 필요하다.
댓글 및 학술 토론
Loading comments...
의견 남기기