베이즈 방법으로 유전 연구의 위너스 커스 극복
초록
본 논문은 초기 GWAS에서 통계적 유의성을 만족한 유전 변이의 효과 추정치가 복제 연구에서 과대평가되는 ‘위너스 커스’를 베이즈 계층모형과 스파이크‑앤‑슬래브 사전분포를 이용해 교정한다. 다양한 사전 설정과 베이즈 모델 평균화를 통해 편향을 감소시키고 추정 분산을 최소화함을 시뮬레이션 및 실제 데이터에서 입증한다.
상세 분석
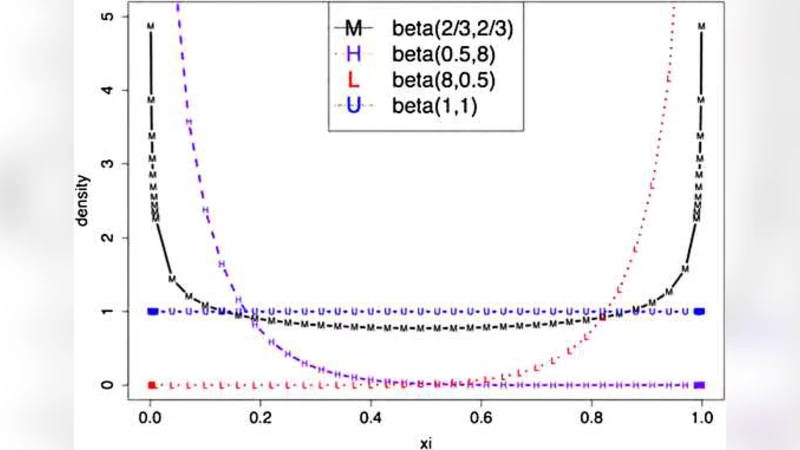
논문은 먼저 위너스 커스 현상이 “같은 데이터로 모델 선택과 파라미터 추정을 동시에 수행”함으로써 발생한다는 점을 강조한다. 기존의 무조건적인 추정치는 선택된 SNP가 실제 연관성보다 우연에 의한 것일 가능성을 반영하지 못한다. 저자들은 이를 해결하기 위해 계층적 베이즈 프레임워크를 제안한다. 핵심은 스파이크‑앤‑슬래브 사전(p(μ|ξ)=ξδ₀(μ)+(1−ξ)f(μ))을 도입해 μ=0(거짓 양성)과 μ>0(진양성) 사이의 불확실성을 모델링하는 것이다. ξ는 베타(a,b) 사전으로 지정되며, a와 b의 선택에 따라 사전 신뢰도가 조정된다(예: a=0.5,b=8은 신호가 실제일 가능성을 높게, a=8,b=0.5는 회의적). 또한 σ²에 대해서는 역감마 사전의 평균을 표본 분산 S²와 일치시키고, 분산의 사전 변동을 크게 설정해 경험적 베이즈 추정을 수행한다.
이론적 부분에서는 정규 모델을 이용해 “조건부 평균이 μ보다 크다”는 사실을 증명하고, 선택된 표본에 대해 μ에 대한 무편향 추정량이 존재하지 않음을 보인다(완전성 정리를 이용). 따라서 베이즈 추정이 편향-분산 절충에서 최적임을 정당화한다.
제안된 방법은 두 단계로 구현된다. 첫째, 스파이크‑슬래브 사전을 이용해 사후 분포를 계산하고, 사후 평균을 μ̂로 사용한다. 둘째, 사전 설정에 따라 여러 모델(예: 비정보적, 보수적, 낙관적)을 만들고, 베이즈 모델 평균화(BMA)를 통해 최종 추정치를 얻는다. BMA는 사전 불확실성을 반영하면서도 과도한 분산 증가를 억제한다.
시뮬레이션에서는 다양한 효과 크기, 표본 크기, 검정력 상황을 고려해 조건부 최대우도추정(MLE)과 비교한다. 결과는 저전력 상황에서 베이즈 추정이 편향을 크게 감소시키고, 분산도 조건부 MLE보다 작으며, 전체 평균 제곱오차(MSE)가 우수함을 보여준다. 실제 데이터(후보 유전자 연구 1건, GWAS 3건)에서도 동일한 경향이 관찰되어, 복제 설계 시 필요한 표본 크기 추정이 보다 현실적이고 보수적으로 제시된다.
결론적으로, 스파이크‑앤‑슬래브 베이즈 모델과 BMA는 위너스 커스로 인한 과대추정 문제를 효과적으로 완화하고, 실용적인 복제 연구 설계에 필요한 정확한 효과 추정치를 제공한다는 점에서 큰 의의를 가진다.
댓글 및 학술 토론
Loading comments...
의견 남기기