GPU로 구현하는 지연 없는 스파이킹 뉴럴 P 시스템 시뮬레이터
초록
본 논문은 지연이 없는 스파이킹 뉴럴 P 시스템(SNP 시스템)을 행렬 형태로 변환하고, CUDA 기반 GPU에서 병렬 연산으로 시뮬레이션하는 방법을 제안한다. 설계·구현 과정을 상세히 설명하고, 모든 자연수(1 제외)를 생성하는 예제 시스템을 통해 성능 및 정확성을 검증한다.
상세 분석
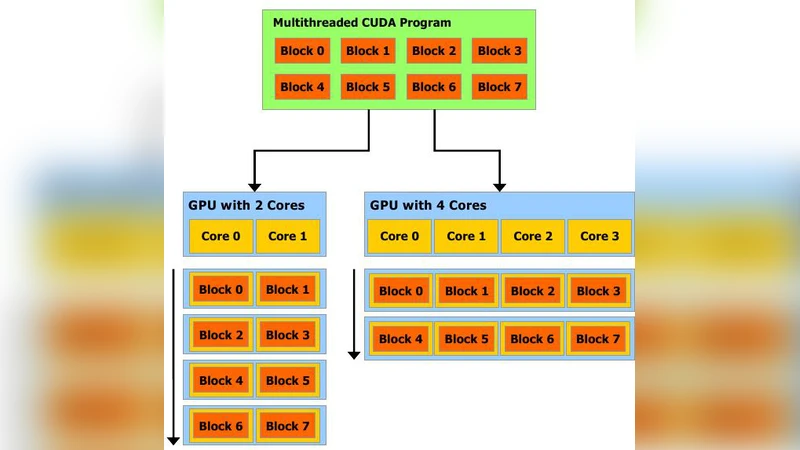
이 연구는 두 가지 핵심 아이디어를 결합한다. 첫째, SNP 시스템을 행렬‑벡터 연산으로 표현함으로써 이론적 모델을 고성능 병렬 하드웨어에 매핑한다는 점이다. 저자는 SNP 시스템의 규칙 집합을 행(row)으로, 뉴런을 열(column)으로 하는 전이 행렬 M을 정의하고, 현재 스파이킹 벡터 S와 구성 벡터 C 사이의 관계를 C_{k+1}=C_k+S_k·M 형태의 선형 방정식으로 정형화한다. 이는 기존의 규칙 적용 과정을 단일 행렬‑벡터 곱으로 압축함으로써, GPU의 SIMD 구조에서 효율적으로 수행될 수 있다.
둘째, CUDA 프로그래밍 모델을 활용해 호스트(CPU)와 디바이스(GPU) 간 데이터 이동을 최소화하고, 각 시뮬레이션 스텝마다 병렬 커널을 호출해 S·M 연산을 수행한다. 구현 단계에서는 메모리 할당, 입력 파일(텍스트 기반 행우선 순서) 로드, cudaMemcpy를 통한 데이터 전송, 그리고 «<N,1»> 형태의 커널 실행을 통해 각 규칙에 대한 적용 여부를 0·1 값으로 계산한다. 커널 내부에서는 각 스레드가 하나의 규칙에 대응하여 소비 스파이크 수(‑c)와 생성 스파이크 수(p)를 행렬 원소에 따라 합산한다. 결과 벡터는 다시 호스트로 복귀해 다음 스텝의 입력으로 사용된다.
성능 측면에서 저자는 GPU의 코어 수가 증가할수록 스파이킹 규칙 수가 많아지는 경우에도 선형적인 속도 향상을 기대할 수 있음을 실험적으로 확인한다. 또한, 행렬이 희소한 경우에도 현재 구현은 밀집 형태를 사용하므로 메모리 사용량이 비효율적일 수 있다는 한계를 인정하고, CSR 등 희소 행렬 포맷 적용을 향후 과제로 제시한다.
알고리즘적 관점에서 중요한 점은 비결정성(non‑determinism) 처리이다. 동일 시점에 여러 규칙이 적용 가능할 때, 하나만 선택하도록 하는 ‘스파이킹 벡터’의 유효성 검증 로직을 호스트 측에서 사전 계산한다. 이는 GPU에서 불필요한 분기와 동기화를 방지해 전체 실행 효율을 높인다.
마지막으로, 논문은 SNP 시스템이 Turing 완전성을 갖는 강력한 계산 모델임을 강조하면서, GPU 기반 시뮬레이터가 대규모 뉴런 네트워크와 복잡한 규칙 집합을 실시간에 가깝게 탐색할 수 있는 기반을 제공한다는 점을 부각한다.
댓글 및 학술 토론
Loading comments...
의견 남기기