알 수 없는 군집을 가진 선형 회귀 모델
초록
본 논문은 실험들 사이에 존재하는 숨겨진 군집 구조와 각 군집별 선형 회귀 관계를 동시에 추정하는 문제를 정의하고, 다섯 가지 알고리즘을 비교한다. Yahoo 학습‑순위 데이터와 합성 데이터 실험을 통해 로컬 회귀(LoR) 방식이 예측 정확도와 계산 효율성 면에서 가장 실용적임을 확인한다.
상세 분석
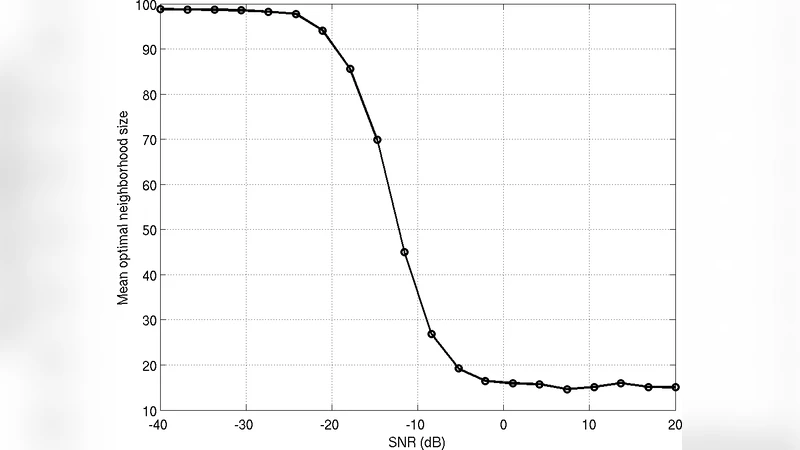
CRUC(Clustered Regression with Unknown Clusters) 문제는 관측된 입력‑출력 쌍이 여러 개의 잠재 군집에 속하며, 각 군집마다 고유한 선형 회귀 파라미터가 존재한다는 가정 하에 전통적인 회귀 분석이 적용되지 못하는 상황을 말한다. 이때 군집 라벨과 회귀 계수는 모두 미지이며, 두 정보를 동시에 추정해야 한다는 이중 불확실성이 핵심 난제이다. 저자들은 EM 기반 방법, K‑means 영감 방법, 행렬 계수 최소화를 위한 Singular Value Thresholding(SVT), 다중 회귀의 Curds‑and‑Whey 변형, 그리고 이웃 기반 로컬 회귀(LoR) 다섯 가지 접근법을 구현하였다. EM은 군집 라벨을 잠재 변수로 두고 기대 단계에서 라벨 확률을, 최대 단계에서 군집별 회귀계수를 업데이트한다. K‑means 방식은 각 실험을 현재 회귀 파라미터와의 잔차 거리로 군집화하고, 군집 중심을 새로운 회귀계수로 재계산한다. SVT는 전체 회귀 계수 행렬을 저‑랭크 근사로 제한함으로써 군집 구조를 암시적으로 복원한다. Curds‑and‑Whey는 다중 반응 변수를 공동으로 예측하면서 군집 정보를 가중치로 활용한다. 마지막으로 LoR는 각 실험에 대해 가장 가까운 K개의 이웃을 찾아 그 이웃들의 데이터를 이용해 로컬 선형 모델을 학습한다. 실험에서는 Yahoo Learning‑to‑Rank Challenge 데이터셋을 사용해 실제 검색 순위 예측에 적용했으며, 시뮬레이션에서는 군집 수와 노이즈 수준을 변형해 알고리즘의 견고성을 평가했다. 결과는 LoR가 K값 선택에 크게 민감하지 않으면서도 평균 제곱 오차(MSE)와 NDCG 점수 모두에서 최상위 혹은 근접한 성능을 보였음을 보여준다. 또한 LoR는 각 실험마다 별도의 전역 모델을 학습할 필요가 없으므로 메모리 사용량과 연산 시간이 크게 절감된다. 저자들은 LoR의 수학적 모델을 분석해 최적 K값이 데이터의 군집 내 변동성 및 군집 간 거리와 직접 연관됨을 증명하고, 이론적 경계와 실험적 결과가 일치함을 확인하였다. 이러한 분석은 CRUC 문제에 대한 실용적인 해결책을 제시함과 동시에, 군집 구조가 명시적으로 드러나지 않을 때도 로컬 정보를 활용하면 충분히 좋은 예측이 가능하다는 중요한 통찰을 제공한다.
댓글 및 학술 토론
Loading comments...
의견 남기기