버그 정보와 코드 특징을 활용한 연관 버그 자동 탐지 시스템
초록
본 논문은 오픈소스 프로젝트의 버그 리포트와 소스코드의 메서드 특징을 결합해, 동일한 로직을 구현한 오버라이드·오버로드 메서드에서 발생할 수 있는 연관 버그를 자동으로 찾아내는 Rebug‑Detector 도구를 제안한다. 버그 리포트에서 자연어 처리(NLP)로 핵심 키워드를 추출하고, 해당 메서드의 코드 특징과 비교·유사도 계산을 통해 잠재적 버그를 식별한다. Apache Lucene‑Java를 대상으로 61개의 연관 버그를 탐지했으며, 그 중 21건은 실제 버그, 10건은 의심 버그로 확인되었다.
상세 분석
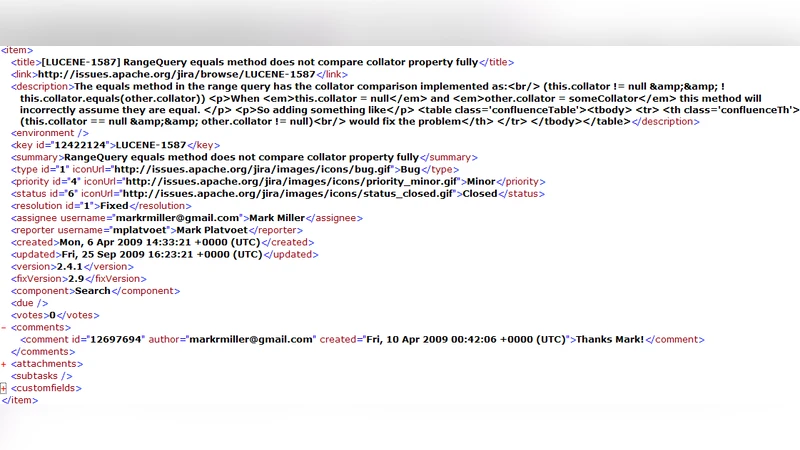
Rebug‑Detector는 크게 네 단계로 구성된다. 첫 번째 단계에서는 버그 트래킹 시스템에 저장된 XML 형식의 버그 보고서를 파싱하고, 자연어 처리 기법을 이용해 클래스명, 메서드명, 그리고 “collator”, “null” 등 도메인 특화 키워드와 조건문 구문을 추출한다. 여기서 핵심은 짧고 비문법적인 버그 설명에서도 의미 있는 토큰을 뽑아내는 것이며, 이를 위해 단어 빈도 기반의 VSM(벡터 공간 모델)과 키워드 가중치를 적용한다.
두 번째 단계는 추출된 버그 메서드와 동일한 이름을 가진 모든 오버라이드·오버로드 메서드를 소스코드에서 찾아내는 과정이다. Java의 다형성 특성을 이용해 클래스 계층 구조를 분석하고, 메서드 시그니처가 일치하는 후보들을 수집한다.
세 번째 단계에서는 각 후보 메서드와 버그 메서드 사이의 코드 유사도를 계산한다. 저자는 ‘공통 부분 문자열’(common substring) 기반의 유사도 측정 방식을 채택했으며, 키워드 빈도와 위치 정보를 가중치로 반영한다. 이때 유사도 값이 사전에 정의된 임계값 θ를 초과하면 해당 메서드를 “연관 버그 후보”로 분류한다.
마지막 단계는 탐지된 후보를 검증하는 것으로, 자동화된 정적 분석 결과와 개발자 피드백을 결합한다. 논문에서는 Lucene‑Java 2.4.1 버전(330개의 클래스, 106,754 LOC)을 대상으로 실험했으며, 전체 탐지 과정은 15.5분 만에 완료되었다. 61개의 연관 버그 중 21개는 실제 버그로 확인되었고, 10개는 아직 보고되지 않은 의심 버그로 분류되었다.
이 시스템의 강점은 버그 리포트에 내재된 도메인 지식을 코드 수준에서 재활용한다는 점이다. 기존의 정적 분석 도구들은 주로 복사‑붙여넣기 패턴이나 API 사용 규칙 위반을 탐지했지만, Rebug‑Detector는 “같은 로직을 구현한 메서드 간의 일관성 위반”이라는 새로운 탐지 차원을 제공한다. 또한, NLP와 코드 마이닝을 결합함으로써 버그 보고서가 비정형 텍스트일지라도 의미 있는 특징을 추출할 수 있다.
하지만 몇 가지 한계도 존재한다. 첫째, 메서드 이름이 동일하지만 실제 동작이 다른 경우(예: 오버로드된 메서드가 다른 파라미터 타입을 가짐)에도 높은 유사도가 계산될 위험이 있다. 둘째, 공통 부분 문자열 기반 유사도는 코드 구조적 차이를 충분히 반영하지 못해, 복잡한 로직 변화는 놓칠 수 있다. 셋째, 임계값 θ 설정이 경험적이며 프로젝트마다 튜닝이 필요하다. 향후 연구에서는 AST(추상 구문 트리) 기반의 구조적 유사도와 머신러닝 기반의 버그 특징 학습을 도입해 정확도를 높이는 방안을 모색할 수 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기