GPU 기반 고속 트랜잭션 처리 엔진 GPUTx
초록
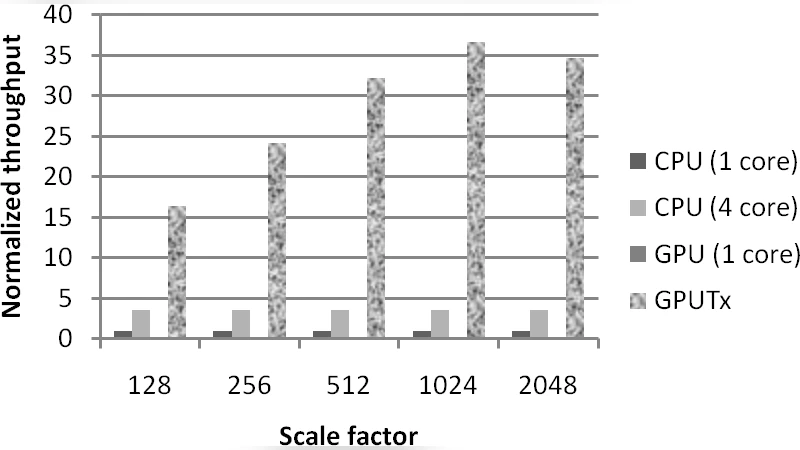
GPUTx는 메모리 내 데이터베이스의 OLTP 워크로드를 GPU에서 대량 실행하도록 설계된 엔진이다. 트랜잭션을 ‘벌크’ 단위로 묶어 단일 GPU 커널로 처리하고, 락 기반·락‑프리 두 가지 무락 전략을 포함한 세 가지 실행 방식을 제안한다. 원자 연산, 대규모 스레드 병렬성, SPMD 특성을 활용한 최적화를 통해 기존 4코어 CPU 대비 4~10배 높은 처리량을 달성하였다.
상세 분석
본 논문은 전통적인 OLTP 시스템이 직면한 ‘수천~수만 건의 소규모 트랜잭션을 짧은 시간에 처리해야 하는’ 요구를 GPU의 대규모 병렬 처리 능력으로 해결하고자 한다. 핵심 아이디어는 벌크 실행 모델이다. 다수의 트랜잭션을 하나의 벌크로 모아 GPU 커널에 전달함으로써, 각 트랜잭션을 개별 스레드 혹은 워프에 매핑하고, GPU가 제공하는 수천 개의 코어에서 동시에 실행한다. 이때 트랜잭션 간 충돌을 관리하기 위해 세 가지 전략을 설계하였다.
-
Lock‑Based Strategy: 전통적인 2‑phase 락(2PL) 방식을 GPU에 그대로 적용한다. 각 데이터 아이템에 뮤텍스 변수를 두고, 스레드가 해당 아이템에 접근할 때 원자 CAS(compare‑and‑swap) 연산을 이용해 락을 획득한다. 충돌이 발생하면 스핀 대기 후 재시도한다. GPU의 원자 연산 지원 덕분에 데드락 방지는 가능하지만, 스핀 대기로 인한 워프 스케줄링 비효율이 존재한다.
-
Optimistic Lock‑Free Strategy A: 트랜잭션을 먼저 읽기 단계와 쓰기 단계로 분리한다. 읽기 단계에서는 충돌 검사를 하지 않으며, 쓰기 단계에서만 원자적 fetch‑and‑add 기반의 버전 번호를 업데이트한다. 버전 검증에 실패하면 해당 트랜잭션을 롤백하고 재시도한다. 이 방식은 충돌이 드문 워크로드에서 높은 스루풋을 보인다.
-
Optimistic Lock‑Free Strategy B (Hybrid): 쓰기 충돌을 최소화하기 위해 데이터 아이템별 write‑set을 미리 정렬하고, 워프 단위로 동일한 아이템에 접근하도록 스케줄링한다. 이렇게 하면 워프 내 스레드가 동일 메모리 라인을 동시에 접근하므로 메모리 coalescing 효과가 극대화되고, 원자 연산의 비용도 감소한다.
논문은 또한 GPU 특유의 SPMD 실행 모델을 활용해, 모든 스레드가 동일한 커널 코드를 실행하되 각 스레드가 담당할 트랜잭션 ID만 다르게 하여 제어 흐름 분기를 최소화한다. 메모리 접근 패턴을 최적화하기 위해 Structure‑of‑Arrays(SOA) 형태로 데이터베이스 레코드를 배치하고, 읽기/쓰기 버퍼를 shared memory에 캐시한다. 이는 글로벌 메모리 접근 지연을 크게 낮추어 전체 처리량을 향상시킨다.
성능 평가에서는 최신 NVIDIA GPU (예: GTX 1080 Ti)와 4코어 Intel Xeon CPU를 동일한 인‑메모리 DBMS 환경에서 비교하였다. TPC‑C와 YCSB 같은 공개 벤치마크를 사용했으며, 최적화된 락‑프리 전략이 가장 높은 10배 가량의 속도 향상을 보였다. 그러나 데이터베이스 크기가 GPU 메모리 용량을 초과하거나, 트랜잭션 충돌 비율이 매우 높은 경우에는 성능 이득이 감소한다는 한계도 명시한다.
이러한 분석을 통해 GPUTx는 대규모 동시성을 요구하는 OLTP 워크로드에 GPU를 효과적으로 적용할 수 있음을 입증한다. 동시에, GPU 메모리 제약, 워프 레벨 스케줄링 복잡성, 그리고 충돌 관리 비용 등 실용적인 제약 조건도 함께 제시한다.
댓글 및 학술 토론
Loading comments...
의견 남기기