클러스터 크기 분포의 고정된 분산 현상 재고
초록
클러스터 크기(N) 분포가 평균
상세 분석
본 논문은 클러스터 크기 N(입자 수)의 확률밀도함수(PDF)가 실제 물리적 자유도보다 훨씬 제한된 형태, 즉 평균
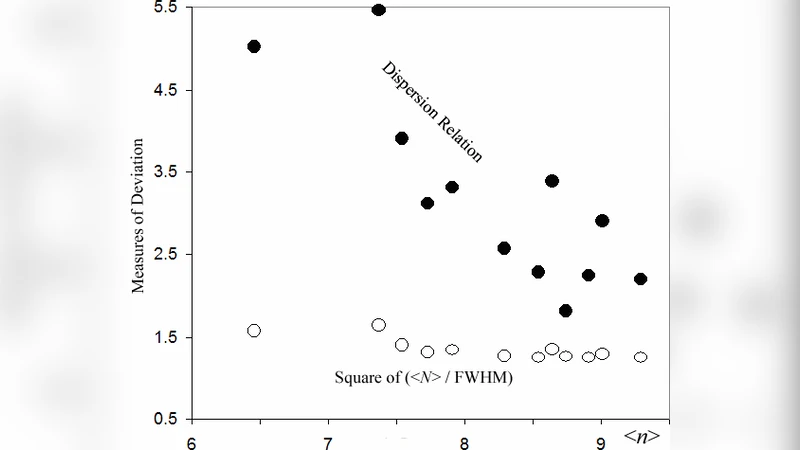
핵심적인 문제는 다음과 같다. 첫째, 로그공간에서의 피팅은 원래 N‑공간의 비대칭성을 과도하게 억제한다. LN은 대칭적인 로그‑분포를 전제로 하여, 실제로는 꼬리가 두껍거나 다중 피크를 가질 수 있는 경우에도 단일 피크와 제한된 폭만을 허용한다. 둘째, EXP는 평균과 분산이 동일한 특성을 가지므로, ⟨N⟩과 FWHM이 수학적으로 동일하게 된다. 따라서 실험적으로 관측된 넓은 분포가 EXP로 강제 맞춰지면, “분산 고정”이라는 착각이 발생한다.
헬륨 클러스터 빔 데이터를 재분석한 결과, 로그‑공간에서 LN·EXP 피팅을 적용하면 χ²는 낮지만, 실제 N‑공간에서의 잔차는 비정상적으로 큰 패턴을 보인다. 특히, 작은 N 영역에서 과소평가되고 큰 N 영역에서 과대평가되는 비대칭 잔차가 관찰된다. 이는 모델이 데이터의 실제 자유도를 충분히 반영하지 못한다는 증거이다.
논문은 이러한 함정을 피하기 위한 대안으로 비파라메트릭 커널 밀도 추정(KDE), 최대 엔트로피(MaxEnt) 방법, 그리고 다중 모드 혼합 모델(Mixture Model)을 제시한다. KDE는 데이터 자체의 구조를 그대로 반영하므로, FWHM이 ⟨N⟩와 일치할 필요가 없으며, 실제 분포의 꼬리와 비대칭성을 정확히 포착한다. MaxEnt는 알려진 제약(예: 평균, 총 입자 수)만을 사용해 가장 무작위적인 분포를 생성하므로, 불필요한 파라미터 제약을 피한다. 혼합 모델은 여러 개의 LN·EXP 성분을 조합해 복합적인 피크와 넓은 꼬리를 동시에 설명할 수 있다.
결론적으로, 클러스터 크기 분포에서 “분산이 고정돼 있다”는 현상은 통계적 모델 선택의 부작용이며, 보다 유연한 분석 프레임워크를 도입해야 한다는 것이 저자들의 주장이다. 이는 클러스터 생산 공정에서 목표 크기 선택성을 향상시키고, 이론적 모델링과 실험 데이터 간의 일관성을 확보하는 데 중요한 시사점을 제공한다.
댓글 및 학술 토론
Loading comments...
의견 남기기