대각선 기반 특징 추출을 이용한 손글씨 알파벳 인식 시스템
초록
**
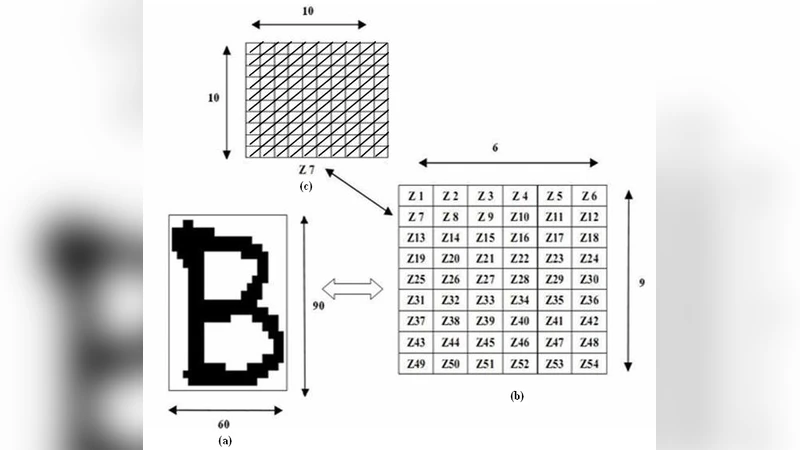
본 논문은 90×60 픽셀 크기로 정규화된 영문 알파벳 이미지를 10×10 픽셀 54개의 구역으로 나눈 뒤, 각 구역의 대각선 픽셀 합을 평균하여 54개의 기본 특징과 행·열 평균 15개의 부가 특징을 추출한다. 추출된 69차원 특징 벡터를 입력으로 하여 2개의 은닉층(각 100노드)과 26개의 출력노드를 갖는 다층 퍼셉트론을 학습시킨다. 실험 결과, 대각선 특징은 기존의 수평·수직 특징보다 인식 정확도가 97.8% (54특징)와 98.5% (69특징)로 크게 향상되었으며, 학습 수렴 속도도 빠른 것으로 확인되었다.
**
상세 분석
**
이 연구는 손글씨 알파벳 인식 분야에서 특징 추출 단계의 효율성을 극대화하려는 시도로서, 기존에 널리 사용되던 수평·수직 투영 방식의 한계를 인식하고 ‘대각선 기반 특징 추출’이라는 새로운 접근법을 제안한다. 핵심 아이디어는 문자 이미지를 10×10 픽셀 크기의 54개 구역으로 분할하고, 각 구역 내 19개의 대각선 라인에 존재하는 전경 픽셀 수를 합산한 뒤 평균값을 구해 하나의 구역 특징으로 만드는 것이다. 이렇게 하면 구역 내부의 구조적 패턴을 보다 균형 있게 포착할 수 있다. 구역별 평균값 외에도 행별·열별 평균을 추가해 총 69개의 특징을 구성함으로써, 지역적 패턴과 전역적 분포 정보를 동시에 제공한다.
특징 차원은 54와 69 두 가지 경우로 실험했으며, 두 경우 모두 동일한 신경망 구조(입력‑100‑100‑출력)와 학습 파라미터(모멘텀 0.9, 적응 학습률, MSE 목표 1e‑6)를 적용했다. 결과적으로 대각선 특징을 사용했을 때 학습 에포크는 54특징 기준 923회, 69특징 기준 854회로 수평·수직 대비 빠른 수렴을 보였으며, 인식 정확도 역시 각각 97.8%와 98.5%로 현저히 높았다. 이는 대각선 라인이 문자 형태의 곡선·斜선 요소를 효과적으로 반영하기 때문으로 해석된다.
데이터셋은 50개의 훈련 세트(각 26자, 다양한 필체)와 570개의 테스트 샘플을 사용했으며, 실험 환경은 MATLAB 7.1 기반이었다. 다만, 훈련·테스트 샘플이 모두 영문 알파벳에 국한되고, 필체 다양성이 제한적이라는 점은 일반화 가능성을 평가하는 데 한계로 작용한다. 또한, 특징 추출 과정에서 구역 내 대각선 라인이 비어 있는 경우 0값을 부여하는 단순 처리 방식은 노이즈에 민감할 수 있다. 향후 연구에서는 더 다양한 언어·스크립트, 복합적인 전처리(예: 스케일·회전 불변성)와 함께, CNN 기반 자동 특징 학습과의 비교를 통해 대각선 기반 방법의 실제 적용 가능성을 검증할 필요가 있다.
**
댓글 및 학술 토론
Loading comments...
의견 남기기