문맥 속 단어와 공동단어의 의미 매핑
초록
본 논문은 문서 집합을 관측자로 삼아 단어와 공동단어 간의 의미 관계를 통계적 패턴(상관관계)과 잠재 변수(요인분석)로 측정하고, 이를 시각화(semantic mapping)하는 방법을 소개한다. Latent Semantic Analysis와 같은 최신 컴퓨터 기반 기법과 활용 가능한 소프트웨어를 제시하며, 분석가가 선택할 수 있는 다양한 옵션을 정리한다.
상세 분석
이 연구는 의미 생성 메커니즘을 “시스템 수준에서 정보가 연결될 때 발생한다”는 관점에서 출발한다. 여기서 시스템은 인간 관찰자일 수도, 혹은 문서 집합과 같은 담론 자체일 수도 있다. 담론을 데이터베이스화하면 각 문서가 단어와 공동단어(co‑word)의 발생 빈도를 행렬 형태로 나타낼 수 있다. 이러한 행렬에 대해 상관관계 분석을 수행하면 단어들 간의 의미적 유사성을 정량화할 수 있으며, 요인분석이나 특이값 분해(SVD)를 적용하면 고차원 공간에서 잠재적인 의미 차원을 추출한다. 이는 전통적인 Latent Semantic Analysis(LSA)의 핵심 원리와 일치한다.
논문은 먼저 “패턴 기반 의미 측정”과 “잠재 변수 기반 의미 측정”을 구분하고, 각각의 장단점을 논한다. 패턴 기반 접근은 단순히 공출현 빈도와 상관계수를 이용해 직관적인 의미 네트워크를 만든다. 그러나 빈도 편향과 희소성 문제에 취약하다. 반면 잠재 변수 접근은 차원 축소를 통해 노이즈를 감소시키고, 의미가 얽힌 복합 구조를 드러낼 수 있다. 특히 요인분석은 각 요인이 어떤 의미 군집을 대표하는지 해석 가능성을 제공한다.
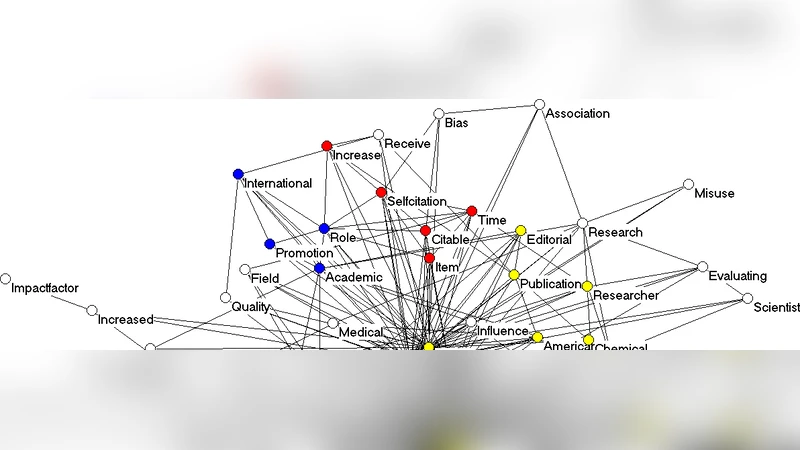
실제 예시에서는 과학 논문 데이터베이스를 대상으로 키워드와 초록에서 추출한 단어들을 행렬화하고, R의 FactoMineR, Python의 scikit‑learn, 그리고 전문 시각화 툴인 VOSviewer, Gephi 등을 사용해 2차원 지도에 투영한다. 결과는 동일 분야 단어가 클러스터를 형성하고, 교차 분야 용어는 연결 고리 역할을 하는 모습을 보여준다.
분석가가 선택할 수 있는 변수로는 (1) 행렬 전처리(스톱워드 제거, 어간 추출, TF‑IDF 가중치 적용), (2) 상관계수 종류(피어슨, 스피어만, 점이중상관), (3) 차원 축소 기법(주성분 분석, 다차원 척도법, t‑SNE, UMAP), (4) 시각화 옵션(노드 크기, 색상, 엣지 두께) 등이 있다. 이러한 선택은 결과 해석에 큰 영향을 미치므로, 연구 목적에 맞는 파라미터 튜닝이 필수적이다.
결론적으로, 의미 매핑은 통계적 패턴과 잠재 구조를 동시에 고려함으로써 보다 풍부하고 직관적인 담론 분석을 가능하게 한다. 컴퓨터 기반 도구와 오픈소스 소프트웨어의 발전으로, 비전문가도 의미 네트워크를 손쉽게 구축하고 시각화할 수 있는 환경이 조성되고 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기