압축 기반 셀룰러 오토마타 동역학 분석
초록
본 논문은 손실 없는 일반 압축 알고리즘을 이용해 프로그램 크기 복잡도(알고리즘적 정보량)를 근사함으로써 셀룰러 오토마타(CA)와 기타 추상 계산 기계의 동역학적 특성을 정량·정성적으로 분석한다. 압축률을 기준으로 CA를 군집화하고, 이 군집이 스티븐 울프람이 제시한 네 가지 행동 클래스와 일치함을 보인다. 또한 초기 조건에 대한 민감도를 나타내는 특성 지수를 정의해 위상 전이와 복원력을 탐지하고, 이 지수가 높은 시스템이 범용 계산 능력을 가질 가능성이 있음을 제시한다.
상세 분석
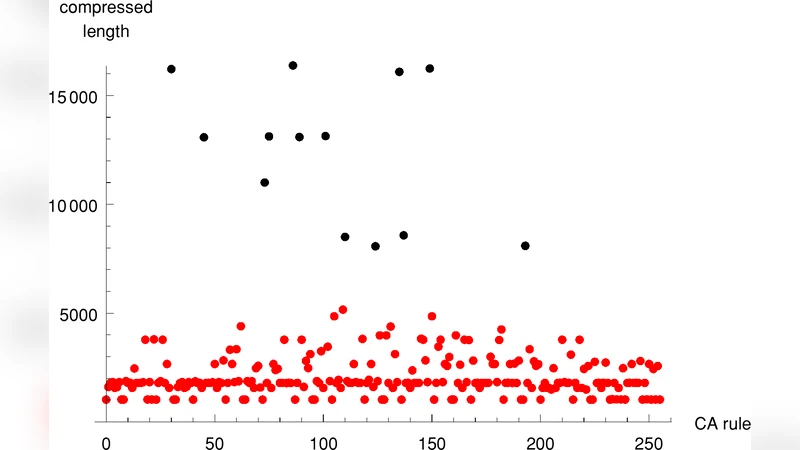
이 연구는 알고리즘적 정보 이론의 핵심 개념인 프로그램 크기 복잡도(Kolmogorov 복잡도)를 직접 계산할 수 없다는 한계를 극복하기 위해, 실제 구현 가능한 손실 없는 압축 프로그램(zlib, gzip 등)을 근사 도구로 채택한다는 점에서 혁신적이다. 압축률은 데이터(여기서는 CA의 시간 진화 스냅샷)가 얼마나 규칙성을 가지고 있는지를 정량화하므로, 복잡도가 낮은(규칙적인) 시스템은 높은 압축률을, 복잡도가 높은(무작위에 가까운) 시스템은 낮은 압축률을 보인다. 논문은 먼저 다양한 1‑차원 이진 CA(규칙 0~255)를 200세대까지 시뮬레이션하고, 각 세대별 상태를 문자열로 전환한 뒤 압축한다. 압축 비율을 시간에 따라 플롯하면, 규칙 30과 같은 클래스 3(혼돈) CA는 압축률이 거의 일정하게 낮은 반면, 클래스 2(주기)와 클래스 1(정적) CA는 초기 몇 세대에서 급격히 압축률이 상승한다는 패턴을 발견한다.
이러한 압축 기반 군집화는 전통적인 Wolfram 분류와 높은 상관관계를 보이며, 특히 경계 상황(예: 클래스 2와 3 사이)에서 기존 분류가 모호할 때 압축 지표가 보다 명확한 구분을 제공한다. 논문은 또한 “특성 지수”(characteristic exponent)를 정의한다. 이는 두 인접 초기 조건(예: 한 셀만 다른 경우)으로부터 시작한 두 CA 진화의 압축률 차이를 로그 스케일로 측정한 뒤, 시간에 대한 기울기를 추정한 값이다. 양의 큰 기울기는 작은 초기 차이가 급격히 증폭됨을 의미하므로, 시스템이 초기 조건에 민감하고 위상 전이가 일어나고 있음을 시사한다. 반대로 기울기가 0에 가깝거나 음수이면, 시스템이 안정적이며 초기 차이가 소멸한다는 뜻이다.
저자는 이 특성 지수를 이용해 여러 CA와 비CA 시스템(예: 비선형 셀룰러 네트워크, 간단한 물리 모델)에서 위상 전이점을 자동으로 탐지하고, 그 강도를 정량화한다. 특히, 특성 지수가 1에 근접하거나 초과하는 경우가 범용 계산 능력을 갖춘 “복잡계”에 해당한다는 가설을 제시한다. 이는 기존에 알려진 범용 CA(예: 규칙 110)와 일치하며, 압축 기반 지표가 범용성의 전조를 포착할 수 있음을 암시한다.
이 논문의 한계는 압축 알고리즘 자체가 구현에 따라 편향될 수 있다는 점이다. 서로 다른 압축기(예: LZMA vs. BZIP2)는 서로 다른 정밀도를 제공하므로, 결과의 재현성을 위해 알고리즘 선택과 파라미터 설정이 표준화돼야 한다. 또한, 압축률이 시간에 따라 수렴하는 현상은 제한된 시뮬레이션 길이와 시스템 크기에 의존하므로, 무한대 규모의 이론적 해석과는 차이가 있다. 그럼에도 불구하고, 손쉬운 구현과 직관적인 해석 가능성 때문에 압축 기반 방법은 복잡계 연구에 실용적인 도구가 될 잠재력이 크다.
댓글 및 학술 토론
Loading comments...
의견 남기기