계층과 대칭을 통한 데이터 마이닝 통합 프레임워크
본 논문은 데이터 분석·마이닝에서 구조를 ‘대칭’으로 정의하고, 계층적 구조를 p‑adic 수와 초거리(ultrametric) 위상으로 수학적으로 구현한다. 계층적 군집, 행·열 순열, 고차원·대규모 데이터의 특수 대칭을 통합적으로 설명하며, 계산 논리·기호 동역학과의 연계 가능성을 제시한다.
저자: Fionn Murtagh
본 논문은 데이터 분석·마이닝에서 “구조는 대칭이다”라는 전통적 관점을 현대 수학적 도구와 연결시켜, 계층적 구조를 중심으로 통합적인 이론 체계를 제시한다. 서두에서는 인간·사회 과학에서 계층이 복잡성의 핵심이라는 Herbert Simon의 견해를 인용하며, 데이터 집합을 관찰 혹은 실험적 도메인에 연결하는 과정에서 대칭이 불변량(invariant)을 제공한다는 점을 강조한다.
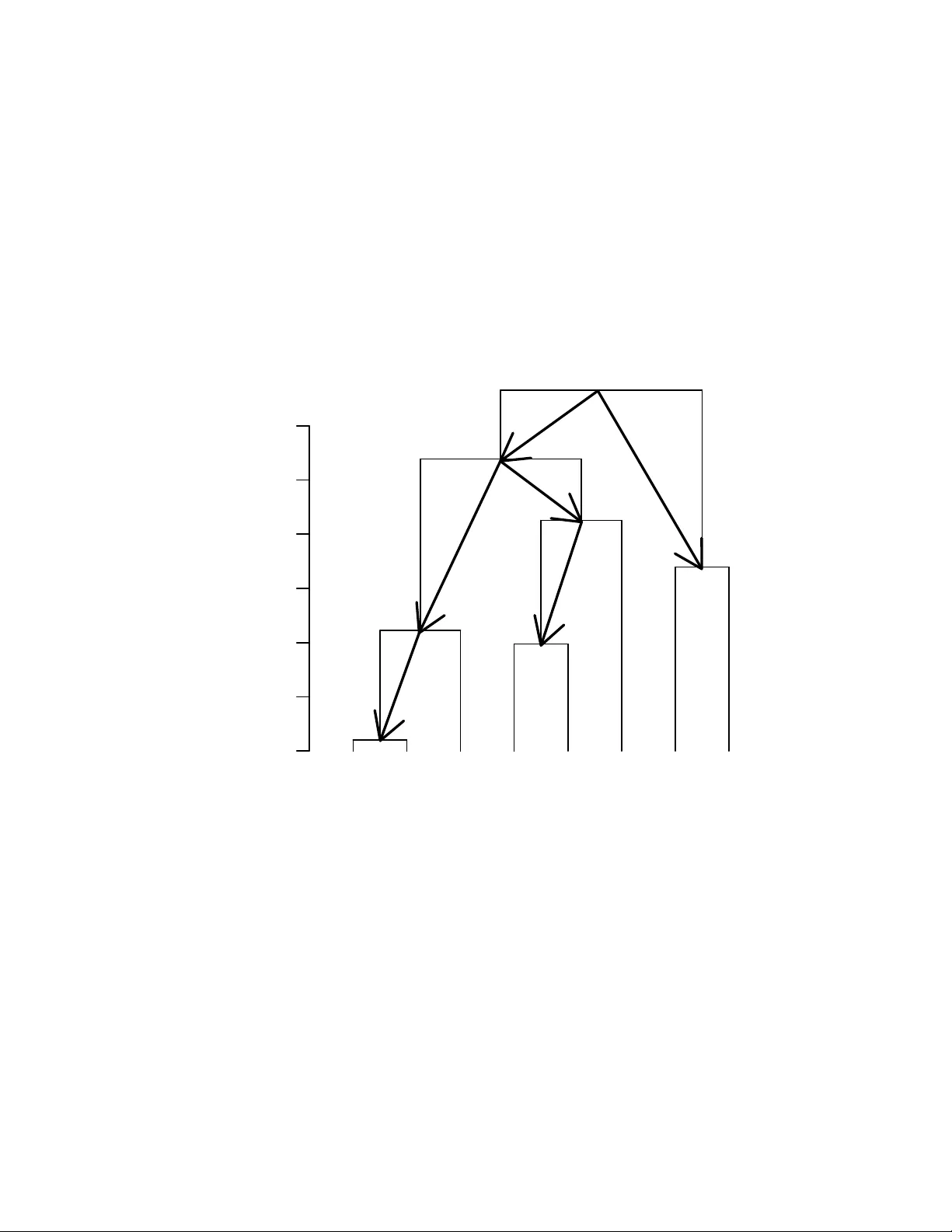
2장에서는 초거리(ultrametric) 위상을 계층의 수학적 표현으로 소개한다. 초거리 공간은 강한 삼각 부등식 d(x,z) ≤ max{d(x,y),d(y,z)}을 만족하며, 이는 모든 삼각형이 등변 또는 작은 밑변을 가진 이등변 형태가 됨을 의미한다. 이러한 특성은 데이터 포인트 간 거리 행렬을 트리 형태로 재배열할 수 있게 하며, 행·열 순열을 통해 초거리 행렬을 ‘클롭엔(clopen)’ 구역으로 시각화한다. 초거리 행렬의 구조적 제약(대각선 0, 행 내 원소 비감소, 동일값 구간 ℓ 이후 원소의 비교 조건 등)은 계층적 군집(dendrogram)과 일대일 대응함을 보이며, 군집 간 포함 관계를 부분 순서(partial order)로 표현한다.
3장에서는 p‑adic 수 체계가 초거리 위상과 어떻게 연결되는지를 설명한다. 실수 체는 아르키메데스적 노름을 사용해 완비화된 ℝ을 얻는 반면, Ostrowski 정리에 따라 모든 소수 p에 대해 비아르키메데스적 노름 |·|ₚ가 존재하고, 이를 이용해 Q를 완비화하면 p‑adic 필드 Qₚ를 얻는다. Qₚ는 로컬 컴팩트하고, 가법·곱법 Haar 측정을 갖는다. p‑adic 확장은 자연수·유리수·실수 체계와 유사한 전개 방식을 가지며, 디지털 데이터(예: DNA·RNA 서열)를 p‑adic 디지털 형태로 인코딩할 수 있다. 5‑adic, 4‑adic, 2‑adic 인코딩 사례를 들어, 서열을 p‑adic 숫자로 변환하면 최장 공통 접두사 거리(‘longest common prefix’)가 초거리 거리와 동일해짐을 보여준다. 이는 서열 비교뿐 아니라 고차원 벡터를 p‑adic 디지털 형태로 변환해 초거리 기반 클러스터링을 수행할 수 있음을 의미한다.
4장에서는 트리 구조 자체가 갖는 대칭을 논한다. 트리는 부분 순서 집합이며, 각 노드는 포함 관계에 따라 계층을 형성한다. 트리의 대칭은 노드 교환(permutation)과 서브트리 재배열을 통해 표현되며, 이는 군집 간 관계를 시각적으로 드러낸다. 또한, 트리 기반 거리(ultrametric)와 p‑adic 전개가 제공하는 불변량은 데이터의 내재적 구조를 파악하는 강력한 도구가 된다.
5장에서는 순열 그룹 Sₙ을 활용한 행·열 순열 기법을 상세히 다룬다. 초거리 행렬을 최적화된 형태로 재배열하기 위해, 작은 값이 대각선 근처에 오도록 순열을 적용한다. 이는 데이터 시각화와 군집 해석에 핵심적인 역할을 하며, 기존의 최적화 기반 클러스터링(예: k‑means, 그래프 파티셔닝)과는 달리 대칭·계층 자체를 직접 탐색한다.
6장에서는 고차원·대규모 데이터에서 나타나는 특수 대칭을 논한다. 차원이 증가함에 따라 거리 분포가 이산화되고, 대부분의 점이 동일한 초거리 구역에 몰리게 된다(‘ultrametricity of high dimensions’). 이는 트리 기반 인덱싱, 근사 최근접 이웃 검색, 그리고 차원 저주를 완화하는 새로운 알고리즘 설계에 활용될 수 있다. 또한, 대규모 데이터의 ‘자연스러운 계층’이 존재한다는 실험적 증거를 제시한다.
마지막으로, 논문은 계산 논리와 기호 동역학과의 연계를 제시한다. 초거리 위상은 비선형 동역학에서 고정점 구조와 유사하며, p‑adic 분석은 논리식 모델 검증, 자동 정리 증명 등에 적용 가능하다. 이러한 교차 분야는 데이터 마이닝을 넘어서 복잡계 과학 전반에 걸친 통합 프레임워크를 제공한다.
결론적으로, 저자는 대칭·계층·p‑adic·초거리라는 네 축을 통해 데이터 마이닝의 이론적 기반을 재구성하고, 이를 바탕으로 고차원·대규모 데이터 분석, 시각화, 그리고 다른 과학 분야와의 융합 연구에 대한 새로운 방향을 제시한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기