화학생물연계 데이터 포털 Chem2Bio2RDF
초록
Chem2Bio2RDF는 유전자, 화합물, 약물, 경로, 부작용, 질병 및 MEDLINE/PubMed 문헌 등 25여 개의 생물·화학 데이터셋을 RDF 형태로 변환하고, Bio2RDF·LODD·DBpedia와 연계한 Linked Open Data 포털이다. D2R 서버 기반의 SPARQL 엔드포인트를 제공하며, RDF 기반 팩셋 브라우저, 직관적인 SPARQL 쿼리 생성기, 문헌 교차 검증 서비스, Cytoscape 시각화 플러그인 등 사용자 친화적 기능을 추가한다. 세 가지 사용 사례를 통해 약물 재창출 및 경로 분석 등 실제 연구에의 활용 가능성을 보여준다.
상세 분석
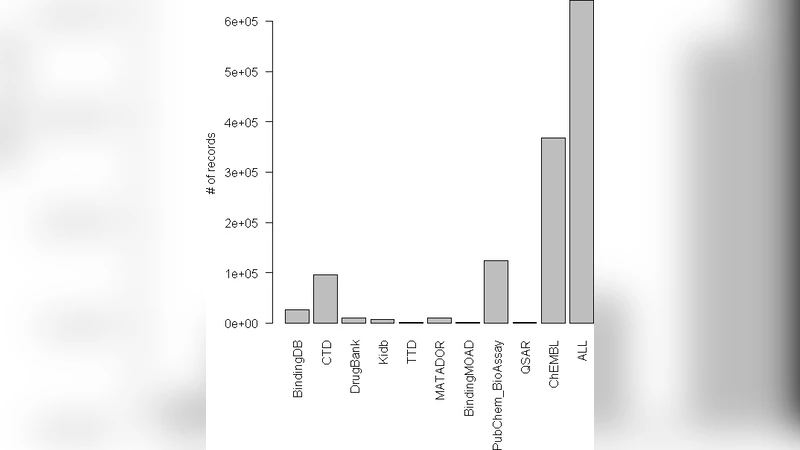
Chem2Bio2RDF는 시스템 화학생물학을 지원하기 위해 기존의 이질적인 데이터베이스들을 RDF 트리플로 통합하고, 전 세계 LOD 생태계와 연결하는 전략을 채택하였다. 우선 25개의 원천 데이터셋을 선정했으며, 이들에는 NCBI Gene, UniProt, ChEMBL, DrugBank, KEGG, SIDER, OMIM, 그리고 MEDLINE/PubMed XML이 포함된다. 각 데이터셋은 스키마 매핑 단계에서 도메인 전문가가 정의한 온톨로지를 기반으로 RDF 변환 규칙이 작성되었다. 변환 과정에서는 URI 설계 원칙을 일관되게 적용해 동일 엔티티에 대한 중복 URI 생성을 방지하고, owl:sameAs 링크를 통해 Bio2RDF, LODD, DBpedia 등 외부 LOD 버블과 연결하였다. 이러한 링크는 교차 검증과 데이터 보강에 핵심적인 역할을 한다.
포털은 D2R 서버 위에 구축되어 관계형 데이터베이스와 RDF 트리플을 실시간 매핑한다. D2R의 매핑 파일은 SPARQL 쿼리 성능을 최적화하기 위해 인덱스와 물리적 테이블 구조를 고려해 설계되었으며, 대규모 질의에 대비해 페이징 및 캐시 전략을 적용하였다. 사용자 인터페이스 측면에서는 RDF Faceted Browser를 제공해 사용자가 클래스·속성·값 기반으로 데이터를 탐색할 수 있게 하였으며, SPARQL Query Builder는 드래그‑앤‑드롭 방식으로 복잡한 질의를 시각적으로 구성하도록 지원한다.
특히 MEDLINE/PubMed 교차 검증 서비스는 화합물·유전자·질병 간 연관성을 문헌 기반으로 확인할 수 있게 하며, 결과는 RDF 형태로 반환되어 후속 분석에 바로 활용 가능하다. Cytoscape 플러그인은 SPARQL 질의 결과를 네트워크 그래프로 시각화함으로써, 연구자가 복합적인 상호작용 맵을 직관적으로 파악하도록 돕는다.
세 가지 사용 사례는 (1) 약물 재창출을 위한 화합물‑질병 연관성 탐색, (2) 경로 기반 부작용 메커니즘 분석, (3) 문헌 기반 타깃 검증을 포함한다. 각각의 사례에서 Chem2Bio2RDF는 기존 데이터베이스만으로는 어려운 복합 질의를 단일 엔드포인트에서 수행하고, 시각화 및 문헌 검증을 통해 결과의 신뢰성을 높였다.
이 논문은 데이터 통합·링크·서비스 제공이라는 전 과정을 하나의 포털에 구현함으로써, 시스템 화학생물학 연구에 필요한 데이터 접근성을 크게 향상시켰다. 다만, RDF 변환 비용과 실시간 질의 성능, 그리고 지속적인 데이터 업데이트 문제는 향후 연구 과제로 남는다.
댓글 및 학술 토론
Loading comments...
의견 남기기