적응형 병렬 온도조절을 이용한 RBM 최대우도 학습
초록
본 논문은 제한볼츠만머신(RBM)의 최대우도 학습에서 발생하는 샘플링 난제를 해결하기 위해, 온도 스케줄을 자동으로 최적화하고 필요에 따라 체인을 동적으로 추가·제거하는 적응형 병렬 템퍼링(Adaptive Parallel Tempering, APT) 기법을 제안한다. 평균 반환 시간(average return time)을 최소화하는 목표 함수를 이용해 온도 집합을 조정하고, 체인 수를 학습 진행 상황에 맞게 조절함으로써 기존 SML‑PT가 요구하던 수작업 튜닝과 높은 계산 비용을 크게 낮춘다. 합성 데이터 실험에서 제안 방법이 기존 고정 온도 PT보다 더 높은 로그우도와 빠른 수렴을 보이며, 샘플링 효율성을 입증한다.
상세 분석
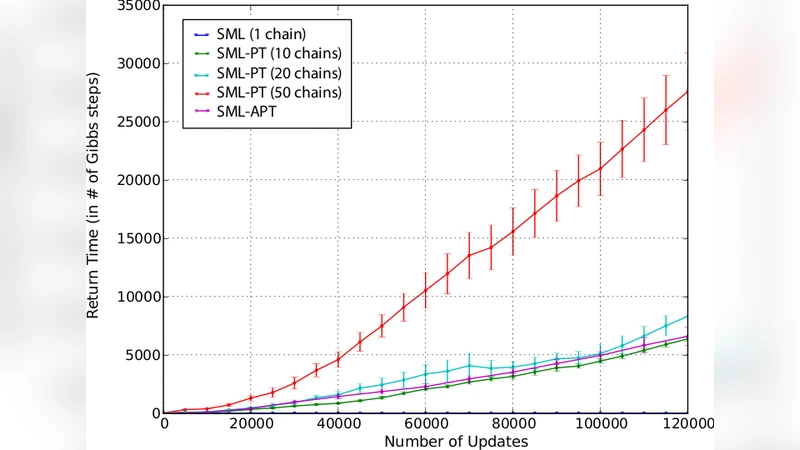
본 연구는 RBM 학습 과정에서 가장 큰 병목 중 하나인 부정상(negative phase) 샘플링의 비에르고딕성 문제를 근본적으로 다룬다. 전통적인 스토캐스틱 최대우도(Stochastic Maximum Likelihood, SML)에서는 단일 마르코프 체인을 사용해 모델 분포를 근사하지만, 학습이 진행될수록 에너지 지형이 급격히 변형돼 체인이 국소 최소점에 머무르는 현상이 빈번해진다. 이를 완화하기 위해 병렬 템퍼링(Parallel Tempering, PT)이 도입되었으며, 서로 다른 온도를 가진 다수의 체인이 주기적으로 교환을 수행함으로써 고온 체인이 저온 체인을 돕는 메커니즘을 제공한다. 그러나 기존 PT는 온도 스케줄을 사전에 고정하고, 체인 수를 임의로 선택해야 하는데, 이 과정이 학습 효율에 큰 영향을 미친다. 온도 간격이 너무 넓으면 교환 확률이 낮아 체인 간 이동이 제한되고, 반대로 너무 촘촘하면 불필요한 계산 비용이 급증한다. 또한, 학습 초기에 낮은 온도 체인이 거의 사용되지 않다가 후기에 급격히 필요해지는 비대칭 현상이 발생한다.
논문은 이러한 트레이드오프를 해소하기 위해 두 가지 핵심 아이디어를 제시한다. 첫째, 평균 반환 시간(average return time, ART)을 최소화하는 목표 함수를 도입한다. ART는 가장 낮은 온도 체인에서 가장 높은 온도 체인까지 한 번 왕복하는 데 걸리는 평균 스텝 수를 의미한다. Katzgraber et al. (2006)의 연구를 확장해, ART를 직접 측정하고 이를 미분 가능한 형태로 변환해 온도 파라미터를 경사 하강법으로 업데이트한다. 이렇게 하면 온도 간격이 자동으로 교환 확률을 최적화하도록 조정된다. 둘째, 체인 수를 동적으로 조절한다. 학습 진행 중에 현재 온도 스케줄에서 교환 성공률이 목표 이하로 떨어지면 새로운 중간 온도 체인을 삽입하고, 반대로 교환 성공률이 과도히 높아 불필요한 중복이 감지되면 체인을 제거한다. 이 과정은 “스플릿·머지” 연산으로 구현되며, 각 체인의 샘플링 통계량(예: 에너지 평균, 분산)을 이용해 삽입·제거 기준을 정한다.
수학적으로는 온도 집합 ({T_i}_{i=1}^K)에 대해 목표 함수
\
댓글 및 학술 토론
Loading comments...
의견 남기기