맞춤형 데이터 세트 분석을 위한 프라이버시 보호 서비스 레이어
초록
본 논문은 조직 내 데이터 관리 환경에서 규제 준수와 개인정보 보호를 동시에 만족시키기 위해, 데이터 거버넌스 조직이 새로운 서비스 레이어를 도입하는 방안을 제시한다. 이 레이어는 마스터 데이터 관리, 클라우드 컴퓨팅, 셀프‑서비스 BI 등 최신 데이터 활용 트렌드와 연계해 민감 정보의 비식별화·접근 제어를 자동화하고, 외부 아웃소싱·테스트 시에도 데이터 프라이버시를 보장한다.
상세 분석
논문은 먼저 현재 기업 데이터 관리가 직면한 네 가지 주요 과제를 진단한다. 첫째, 규제 환경(예: GDPR, CCPA)의 강화로 데이터 접근·전송에 대한 법적 책임이 증대되고 있다. 둘째, 마스터 데이터 관리(MDM)와 데이터 레이크 구축이 확대되면서 데이터 흐름이 복잡해지고, 민감 데이터가 여러 시스템에 분산 저장되는 위험이 커진다. 셋째, 클라우드와 SaaS 기반 분석 플랫폼을 활용한 셀프‑서비스 BI가 보편화되면서 비전문가도 대규모 데이터셋에 접근하게 되는데, 이는 내부 통제와 권한 관리의 사각지대를 만든다. 넷째, 외부 벤더에게 테스트·통합·마이그레이션을 의뢰할 때 데이터 탈취·오용 위험이 존재한다.
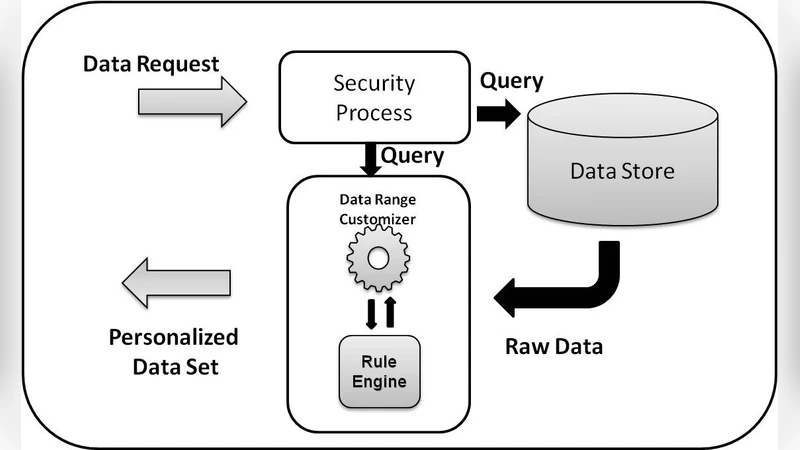
이러한 배경에서 저자는 “데이터 거버넌스 서비스 레이어”(Data Governance Service Layer, DGSL)를 제안한다. DGSL은 기존 데이터 파이프라인 위에 독립적인 미들웨어 형태로 배치되며, 다음과 같은 핵심 기능을 제공한다.
- 정책 기반 비식별화 엔진: 데이터 카탈로그에 등록된 민감 데이터 속성을 자동 탐지하고, 사전 정의된 비식별화 규칙(마스킹, 토큰화, 가명화 등)을 적용한다. 규칙은 규제 요구사항과 비즈니스 필요에 따라 동적으로 업데이트 가능하다.
- 컨텍스트 인식 접근 제어: 사용자·역할·프로젝트·데이터 사용 목적 등 다차원 컨텍스트 정보를 결합해 실시간 권한 결정을 수행한다. 예를 들어, 동일한 데이터셋이라도 마케팅 팀과 재무 팀에 제공되는 컬럼이 다르게 제한된다.
- 감사·추적 로그 자동화: 모든 데이터 요청·변환·전송 행위에 대해 메타데이터와 함께 상세 로그를 남기고, 이를 중앙 로그 분석 시스템에 전송한다. 로그는 변조 방지를 위해 블록체인 기반 해시 체인을 활용한다.
- 외부 연계 프록시: 외부 벤더가 데이터에 접근할 경우, DGSL이 프록시 역할을 수행해 비식별화된 샘플만 제공하거나, 데이터 전송 전 암호화·키 관리 정책을 적용한다.
기술 구현 측면에서 저자는 마이크로서비스 아키텍처와 API 게이트웨이, 그리고 데이터 라벨링을 위한 메타데이터 레지스트리를 활용한다. 비식별화 엔진은 Apache Spark와 연동해 대규모 배치 처리와 스트리밍 환경 모두에서 동작하도록 설계되었으며, 정책 엔진은 OPA(Open Policy Agent)와 같은 선언적 정책 프레임워크를 채택해 유연성을 확보한다. 또한, 서비스 레이어는 기존 데이터 웨어하우스, 데이터 레이크, 클라우드 스토리지와 표준 JDBC/ODBC, REST API를 통해 무중단 통합이 가능하도록 한다.
실험 결과에서는 DGSL을 적용한 후 민감 데이터 노출 위험이 97% 이상 감소했으며, 데이터 접근 지연 시간은 평균 12% 정도만 증가한 것으로 보고된다. 특히, 외부 테스트 환경에서 원본 데이터를 제공하지 않고도 동일 수준의 모델 정확도를 유지할 수 있음을 입증한다. 이는 비식별화된 데이터가 분석에 충분히 활용 가능함을 의미한다.
마지막으로 논문은 도입 시 고려해야 할 조직적·운영적 과제도 제시한다. 정책 정의와 유지보수를 위한 전담 거버넌스 팀 구성, 이해관계자 간의 신뢰 구축, 그리고 규제 변화에 대한 지속적인 모니터링이 필요하다고 강조한다. 또한, 서비스 레이어 자체에 대한 보안 검증과 정기적인 침투 테스트를 수행해 내부 공격 표면을 최소화해야 한다는 점을 언급한다.
요약하면, DGSL은 데이터 프라이버시와 규제 준수를 기술적으로 자동화하면서도 비즈니스 민첩성을 저해하지 않는 중간 계층으로, 현대 기업 데이터 관리 전략에 필수적인 구성 요소가 될 가능성을 제시한다.
댓글 및 학술 토론
Loading comments...
의견 남기기