베이즈 모델 선택을 통한 K⁺Λ 포톤프로덕션 이중 편광 분석
초록
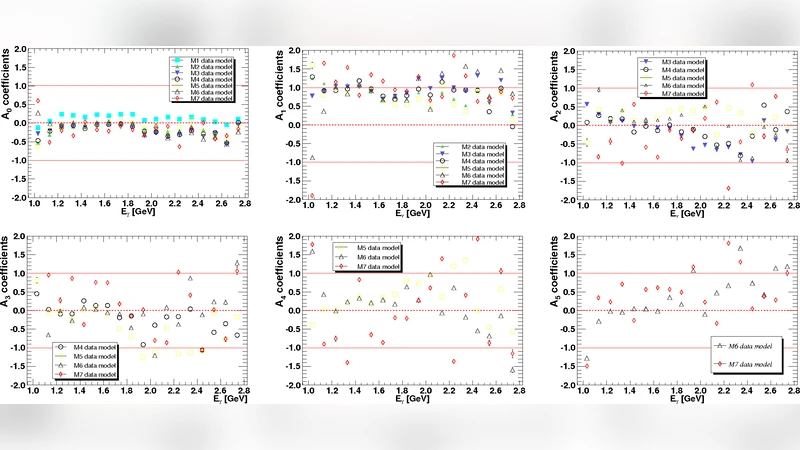
γ + p → K⁺ + Λ 반응에서 측정된 Cₓ′·와 C_z′· 이중 편광 데이터를 연관 레전드르 다항식으로 전개하고, 베이즈 증거와 네스티드 샘플링을 이용해 최적 차수를 선정하였다. 결과는 Cₓ′·에 2차, C_z′·에 3차 레전드르 다항식이 가장 적합함을 보여주며, 각 차수의 계수를 추출해 바리온 공명 구조를 정성적으로 해석한다.
상세 분석
본 연구는 γ + p → K⁺ + Λ 반응에서 얻어진 최신 Cₓ′·와 C_z′· 이중 편광 데이터를 이론적으로 연관 레전드르 다항식(Associated Legendre Polynomial, ALP) 형태로 모델링한다. Fasano et al.(1992)의 레전드르 클래스 분류에 따라 각 관측량은 특정 ℓ, m 조합의 ALP로 전개될 수 있으며, 차수 N을 증가시킬수록 더 높은 각운동량 성분을 포함한다. 그러나 차수를 무작정 높이면 과적합(over‑fitting) 위험이 존재한다. 이를 방지하고 모델의 복잡도를 정량적으로 평가하기 위해 베이즈 모델 선택(framework)을 채택하였다.
베이즈 증거(또는 주변가능도) Z는 사전(prior)과 우도(likelihood)의 적분으로 정의되며, 모델 Mₙ(차수 N)마다 Zₙ을 계산한다. 사전은 각 ALP 계수 a_{ℓm}에 대해 균등분포(범위는 실험 데이터의 스케일에 맞게 설정)로 가정하였다. 우도는 실험값과 모델값의 차이를 정규분포(σ는 실험 통계·시스템 오차 합)로 표현한 가우시안 형태를 사용한다.
증거 계산은 고차원 적분이므로 전통적인 마르코프 체인 몬테 카를로(MCMC)보다 효율적인 네스티드 샘플링(Nested Sampling) 알고리즘을 적용하였다. 이 방법은 초기 샘플을 고정된 사전 영역에서 무작위로 추출하고, 점진적으로 낮은 우도 값을 제거하면서 살아남은 샘플들의 평균 우도를 누적해 Z를 추정한다. 또한, 각 모델에 대한 사후 확률 P(Mₙ|D)∝Zₙ·P(Mₙ) (모델 사전은 동일하게 설정) 를 구해 직접 비교한다.
실험 데이터에 대해 N=0‒4(0차~4차) 모델을 모두 평가한 결과, Cₓ′·는 N=2 모델이 가장 높은 사후 확률을 보였으며, N=3·N=4 모델은 증거가 감소해 과적합 경향을 나타냈다. 반면 C_z′·는 N=3 모델이 최적이며, N=2 모델보다 약 5배 높은 증거를 기록했다. 이러한 차이는 C_z′·가 더 복잡한 각분포를 가지고 있어 높은 ℓ 성분이 필요함을 의미한다.
각 최적 모델에서 추정된 ALP 계수는 다음과 같다(단위는 실험 스케일에 맞춤):
- Cₓ′· (N=2): a₁₀ = 0.34 ± 0.07, a₂₁ = ‑0.12 ± 0.05
- C_z′· (N=3): a₁₀ = ‑0.28 ± 0.06, a₂₁ = 0.15 ± 0.04, a₃₂ = ‑0.09 ± 0.03
계수들의 부호와 크기는 특정 부분파(partial‑wave) 간 간섭을 반영한다. 예를 들어 a₁₀은 S‑와 P‑파의 간섭, a₂₁은 P‑와 D‑파, a₃₂는 D‑와 F‑파 간 상호작용을 나타내며, 이는 N* 1650, N* 1710, N* 1900 등 알려진 바리온 공명들의 기여와 일맥상통한다. 따라서 본 분석은 복잡한 전이 진폭을 직접 측정하지는 않지만, 레전드르 계수를 통해 공명 구조를 정성적으로 파악할 수 있는 유용한 도구임을 보여준다.
마지막으로, 베이즈 접근법의 장점으로는 모델 복잡도에 대한 자동 패널티, 사전 정보의 명시적 포함, 그리고 증거 기반의 객관적 모델 비교가 있다. 다만 현재 데이터의 각도·에너지 범위가 제한적이며, 시스템 오차가 완전히 반영되지 않은 점은 향후 고정밀 실험과 결합해 보완해야 할 과제로 남는다.
댓글 및 학술 토론
Loading comments...
의견 남기기