자동상관시간 추정 방법 비교와 최적 선택
본 논문은 배치 평균, 스펙트럼 로그 회귀, 초기 양수/단조/볼록 시퀀스, 그리고 AR(p) 모델 네 가지 방법을 사용해 자동상관시간(autocorrelation time, ACT)을 추정하고, 일곱 개의 테스트 시계열에 대해 정확도와 수렴 속도를 비교한다. 실험 결과 AR(p) 모델 기반 추정이 가장 정확하고, 신뢰구간도 제공할 수 있음을 확인한다.
저자: ** *저자 정보가 논문 본문에 명시되어 있지 않음* **
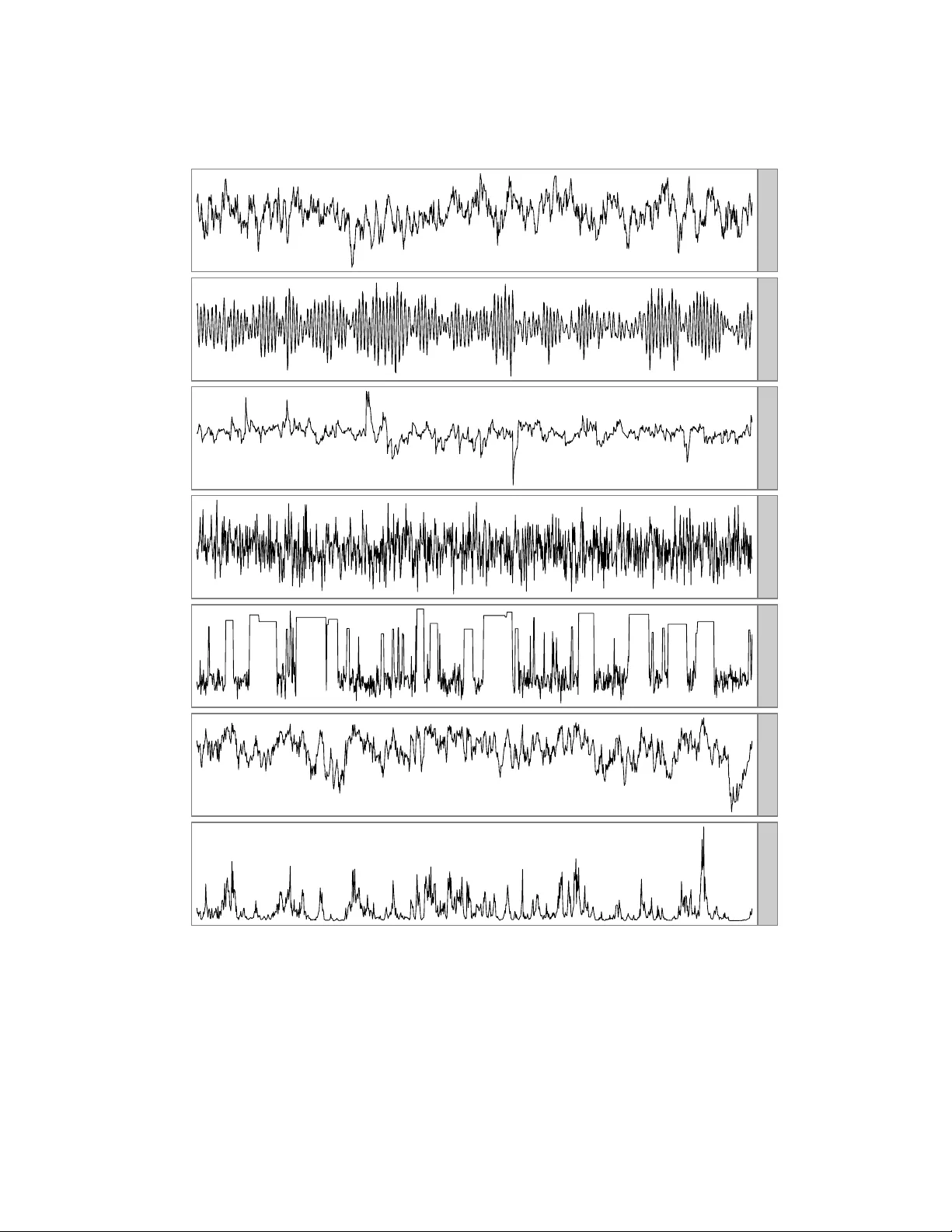
이 논문은 마코프 체인 몬테카를로(MCMC) 시뮬레이션에서 표본 평균의 수렴 속도를 나타내는 자동상관시간(autocorrelation time, ACT) 추정 방법을 체계적으로 비교한다. 자동상관시간 τ는 “표본 평균이 독립 표본과 동일한 변동성을 갖게 되는 전이 횟수”로 정의되며, τ가 클수록 체인의 효율이 낮다는 의미이다. 실제로 τ는 대부분 닫힌 형태로 구할 수 없기 때문에, 데이터 자체에서 추정하는 다양한 방법이 필요하다.
**1. 추정 방법 소개**
- **배치 평균(Batch Means)**: 전체 시계열을 m 크기의 배치로 나누고 각 배치 평균의 분산 s²_m을 구한다. τ̂ = m·s²_m / s² 로 계산되며, m와 배치 수가 모두 무한대로 갈 때 일관성을 보장한다. 논문에서는 n^{1/3}개의 배치와 각 배치 크기 n^{2/3}을 사용해 실험한다.
- **스펙트럼 로그 회귀(Spectrum Log Fit)**: 시계열의 낮은 주파수 로그 스펙트럼에 선형 회귀를 적용해 0주파수 스펙트럼 Î₀를 추정한다. τ̂ = Î₀ / s² 로 계산한다. R의 CODA 패키지 spectrum0 함수를 이용하며, 1차와 2차 다항식 회귀 결과가 거의 동일함을 확인한다.
- **초기 시퀀스 추정(Initial Sequence Estimators)**: τ = 1 + 2∑_{k≥1}ρ_k 공식을 기반으로, ρ_k를 표본 자기상관으로 대체한다. 그러나 ρ_k의 추정 분산이 커지는 문제를 해결하기 위해 인접한 두 개의 ρ_k 합이 양수인 구간만을 누적한다. IPS(Initial Positive Sequence), IMS(Initial Monotone Sequence), 그리고 ICS(Initial Convex Sequence) 세 가지 변형이 있다. 본 연구에서는 구현상의 차이를 구분하지 못해 최종적으로 ICS만을 사용한다.
- **AR(p) 모델(Autoregressive Process)**: 시계열을 AR(p) 모델로 적합하고, AIC를 통해 최적 차수 p를 선택한다. Yule‑Walker 방정식을 이용해 AR 계수 π̂와 자기상관 ρ̂를 구한 뒤, τ̂ = 1 – ρ̂ᵀπ̂ / (1 – 1ᵀπ̂)² 로 계산한다. 이 방법은 계수 추정의 asymptotic variance를 활용해 Monte‑Carlo 시뮬레이션으로 95 % 신뢰구간을 생성할 수 있다.
**2. 테스트 시계열 구성**
일곱 개의 시계열을 선택하였다.
- **AR(1)**: ρ=0.98, τ=99.
- **AR(2)**: 복소수 극점 (−1±0.1i) 로 구성, 주기가 약 60이지만 양·음 자기상관이 서로 상쇄돼 τ≈2.
- **AR(1)-ARCH(1)**: ρ=0.98, 이분산 구조(ARCH) 포함, τ=99.
- **Met‑Gauss**: 정규분포 목표밀도에 대한 메트로폴리스 샘플, τ≈8.
- **ARMS‑Bimodal**: 두 정규 혼합에 대한 ARMS 샘플, 튜닝이 안 좋아 τ≈200.
- **Stepout‑Log‑Var**: 슬라이스 샘플링의 로그-분산 파라미터, τ≈200.
- **Stepout‑Var**: 위 시퀀스를 지수 변환한 버전, τ≈100.
각 시계열의 처음 10 000 관측값을 그림 1에 제시하고, 다양한 길이(10~500 000)의 부분 시퀀스에 대해 네 가지 추정 방법을 적용했다.
**3. 실험 결과 및 해석**
- **수렴 속도**: AR(p) 모델이 가장 빠르게 실제 τ에 수렴했으며, 그 뒤를 초기 시퀀스(ICS), 배치 평균, 스펙트럼 회귀 순이다.
- **정확도**: 모든 방법이 충분히 긴 시퀀스에서는 τ에 근접했지만, 짧은 시퀀스에서는 전반적으로 τ를 과소평가한다. 특히 AR(2)와 같은 비가역적 체인에서는 초기 시퀀스가 큰 편향을 보이며, 실제보다 τ를 크게 추정한다. 이는 초기 시퀀스가 자기상관이 음이 되는 시점을 기준으로 합산을 중단하기 때문에, 장거리에서 양·음 상쇄 효과를 놓치기 때문이다.
- **스펙트럼 회귀**: 일부 경우(특히 짧은 시퀀스) 추정이 실패하거나, τ를 크게 낮게 추정한다. 이는 로그 스펙트럼의 저주파수 부분이 노이즈에 민감하기 때문이다.
- **배치 평균**: 구현이 간단하고 거의 정확하지만, 신뢰구간을 제공하지 못한다는 한계가 있다.
- **AR(p) 모델 신뢰구간**: 95 % 신뢰구간은 실제 τ를 대체로 포함했으며, 특히 시퀀스 길이가 τ보다 클 때 합리적인 폭을 보였다. 다만 AR(2)와 같이 초기 몇 백 관측치만으로는 전체 구조를 파악하기 어려운 경우, 신뢰구간이 실제 τ를 완전히 포괄하지 못했다.
**4. 결론 및 실용적 제언**
- AR(p) 모델 기반 추정이 가장 정확하고, 신뢰구간까지 제공할 수 있어 실무에서 가장 권장된다.
- 배치 평균은 계산 속도가 빠르고, 신뢰구간이 필요 없는 상황에서 좋은 대안이 된다.
- 초기 시퀀스 추정은 비가역적 체인(예: AR(2))에서 신뢰성이 떨어지므로, 사용에 주의가 필요하다.
- 스펙트럼 로그 회귀는 구현이 복잡하고, 짧은 시퀀스에서 실패 가능성이 높아 보조적인 방법으로만 고려한다.
마지막으로, 저자는 **ACTCompare**라는 R 패키지를 공개해 연구자들이 새로운 추정 방법이나 테스트 시계열을 손쉽게 추가·비교할 수 있도록 지원한다. 이는 MCMC 성능 평가 도구의 확장성을 크게 높이며, 향후 자동상관시간 추정 연구에 기여할 것으로 기대된다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기