GPU 기반 병렬 희소 행렬 해법을 이용한 전기 기계 시뮬레이션
초록
본 논문은 전기 기계 시뮬레이션에 사용되는 대규모 대칭 양정밀 희소 행렬을 GPU에서 Conjugate Gradient(CG) 방법으로 풀기 위한 구현과 성능 평가를 제시한다. CSR·Symmetric‑CSR·CSC 형식으로 저장된 행렬에 대해 전용 SpMV 커널을 설계하고, CUDA의 BLAS와 원자 연산을 활용해 스칼라·벡터 연산을 가속한다. 실험 결과, GTX 280에서 double‑precision CG가 CPU 대비 6배 이상, 단정밀도 버전이 5.8배 가속됨을 확인하였다. 대칭 저장은 메모리 절감 효과가 있으나, 현재 구현에서는 반복적인 원자 연산으로 인해 성능 저하가 발생한다는 한계도 제시한다.
상세 분석
이 연구는 전자기 유한요소 해석에서 필수적인 대규모 선형 시스템 Ax = b 를 GPU 기반 병렬 환경으로 옮겨 실행함으로써 계산 시간을 획기적으로 단축하려는 시도이다. 핵심 알고리즘은 대칭 양정밀 행렬에 특화된 Conjugate Gradient(CG)이며, CG는 대칭 양정(Positive‑Definite) 행렬에 대해 수렴성이 뛰어나고, 희소 행렬에 대한 메모리 접근 패턴이 비교적 규칙적이어서 GPU의 메모리 대역폭을 효율적으로 활용할 수 있다.
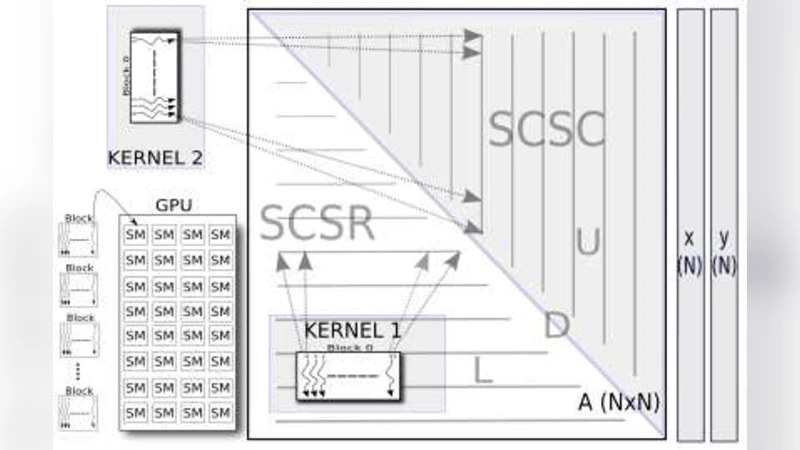
GPU 하드웨어는 수천 개의 스레드가 동시에 실행되는 SM(Stream Multiprocessor) 구조를 갖추고 있으며, 각 SM은 16 KB의 공유 메모리와 32개의 스레드로 구성된 워프(warp)를 제공한다. 논문은 이러한 구조를 고려해 세 가지 SpMV 커널을 설계하였다. 첫 번째는 일반 CSR 형식에 대해 각 스레드가 행(row) 하나를 담당하는 전통적인 방식이며, 두 번째·세 번째는 대칭 CSR 및 CSC 형식을 이용해 L + D와 U 부분을 별도 커널에서 처리한다. 대칭 저장은 메모리 사용량을 절반으로 줄이지만, U 부분을 계산할 때 원자 연산(atomicAdd)을 사용해 y = Ax 결과 벡터에 동시 쓰기를 방지한다. 원자 연산은 직렬화 효과를 가져와 메모리 대역폭을 제한하므로, 대칭 저장이 오히려 성능을 저하시킨다는 결과가 도출되었다.
연산별 성능 분석에서는 dot‑product와 AXPY는 CuBLAS 라이브러리를 그대로 호출해 GPU에서 거의 즉시 수행되지만, SpMV가 전체 실행 시간의 대부분을 차지한다는 점을 강조한다. 특히 double‑precision SpMV는 5.966 ms(CPU) 대비 0.005 ms(GTX 280) 로 1,200배 이상의 가속을 보였으며, 단정밀도에서는 0.013 ms로 더욱 빠른 처리 속도를 기록했다. 전체 CG 루프는 2392 ms(CPU) 대비 370 ms(GTX 280) 로 약 6.4배 가속되었다.
이와 같이 GPU를 활용한 희소 행렬 솔버는 메모리 대역폭과 연산 병렬성을 동시에 활용해 전통적인 CPU 기반 솔버에 비해 현저한 속도 향상을 제공한다. 그러나 대칭 저장 방식에서 발생하는 원자 연산 병목은 향후 커널 최적화(예: 색칠(coloring) 기법, 행/열 분할, 워프 수준의 협조적 연산) 등을 통해 개선될 필요가 있다. 또한, 현재 실험은 단일 GPU와 단일 CG 루프에 국한되었으므로, 다중 GPU 확장성 및 복합 전기기계 시뮬레이션 파이프라인과의 연계성에 대한 추가 연구가 요구된다.
댓글 및 학술 토론
Loading comments...
의견 남기기