대규모 데이터 분석을 위한 알고리즘과 통계의 융합 전략
초록
본 논문은 대규모 과학·인터넷 데이터에서 중요한 열(특징)과 군집(커뮤니티)을 선택하는 두 사례를 통해 알고리즘적 설계와 통계적 모델링이 어떻게 상호 보완적으로 작용할 수 있는지를 보여준다. DNA SNP 행렬에 대한 열 선택은 레버리지 점수 기반 샘플링과 CUR 분해를, 소셜 네트워크 그래프에 대한 군집 선택은 전도성 최소화와 스펙트럴 방법을 결합해 효율적이고 이론적으로 보장된 해법을 제시한다.
상세 분석
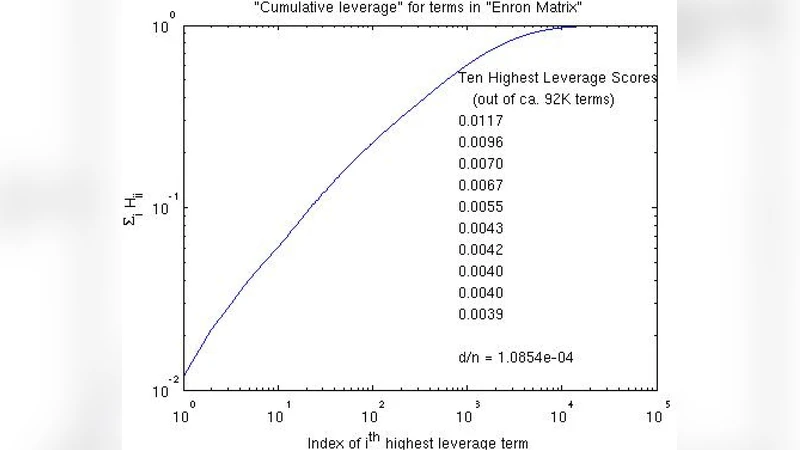
논문은 먼저 대규모 데이터 분석에서 ‘최악의 경우’ 성능을 보장하면서도 실제 데이터의 통계적 구조를 활용할 수 있는 알고리즘 설계가 필요하다는 점을 강조한다. 첫 번째 사례는 DNA 단일 뉴클레오타이드 다형성(SNP) 데이터를 행렬 형태로 표현한 뒤, 중요한 열(즉, 변이 위치)을 선택하는 문제이다. 여기서 저자는 전통적인 고정 차원 축소 기법과 달리, 행렬의 레버리지 점수(leverage scores)를 계산해 높은 점수를 가진 열을 확률적으로 샘플링한다. 레버리지 점수는 행렬의 왼쪽 특이벡터 공간에서 각 열이 차지하는 기여도를 정량화한 것으로, 통계적으로는 열이 전체 데이터 변동을 얼마나 설명하는지를 나타낸다. 이러한 샘플링은 CUR 분해와 결합되어, 원본 행렬 A를 A≈C U R 형태로 근사한다. C와 R은 각각 선택된 열과 행이며, U는 작은 핵심 행렬이다. 저자는 이 방법이 기존의 최적화 기반 열 선택보다 O(k log k) 시간 복잡도로 동일한 근사 오차를 달성함을 증명한다. 또한, 레버리지 점수 추정에 사용되는 랜덤 투사(random projection) 기법은 메모리 사용량을 크게 줄이면서도 높은 정확도를 유지한다는 실험 결과를 제시한다.
두 번째 사례는 소셜·정보 네트워크를 그래프로 모델링하고, 의미 있는 커뮤니티를 찾아내는 문제이다. 여기서는 그래프의 전도성(conductance)을 최소화하는 클러스터가 ‘좋은’ 커뮤니티로 정의된다. 전통적인 스펙트럴 클러스터링은 라플라시안 행렬의 두 번째 고유벡터(Fiedler vector)를 이용해 정규화 컷을 찾지만, 최악의 경우 성능 보장이 약하고 노이즈에 민감하다. 논문은 이를 보완하기 위해, 랜덤 워크 기반의 마코프 체인 전이 행렬을 이용한 ‘전도성 기반 샘플링’을 제안한다. 이 과정에서 각 정점의 ‘중심성 점수’를 계산하고, 높은 점수를 가진 정점을 초기 시드로 선택한다. 이후, 반전도성(negative conductance) 최적화를 위한 반전도성 최소화 알고리즘을 적용해 클러스터를 확정한다. 저자는 이 방법이 확률적 그래프 모델(예: stochastic block model) 하에서 전통적인 스펙트럴 방법보다 더 높은 정확도와 더 빠른 수렴 속도를 보인다고 주장한다. 또한, 알고리즘 복잡도는 O(m log n) (m은 엣지 수, n은 정점 수) 로, 대규모 실시간 네트워크 분석에 적합하다.
전체적으로 논문은 두 사례 모두에서 ‘알고리즘적 최악의 경우 보장’과 ‘통계적 데이터 구조 활용’이라는 두 축을 동시에 만족시키는 설계 원칙을 제시한다. 레버리지 점수와 전도성 중심성이라는 통계적 지표를 이용해 샘플링·시드 선택을 수행하고, 이후에 효율적인 최적화 절차를 적용함으로써, 이론적 오류 한계와 실험적 성능 사이의 격차를 크게 줄였다. 이러한 접근은 앞으로 고차원 바이오인포매틱스 데이터나 거대 소셜 네트워크와 같은 복합 데이터셋에 대한 확장 가능하고 신뢰성 있는 분석 프레임워크를 제공한다는 점에서 큰 의미를 가진다.
댓글 및 학술 토론
Loading comments...
의견 남기기