DCSP에서 효율적인 지식베이스 관리
초록
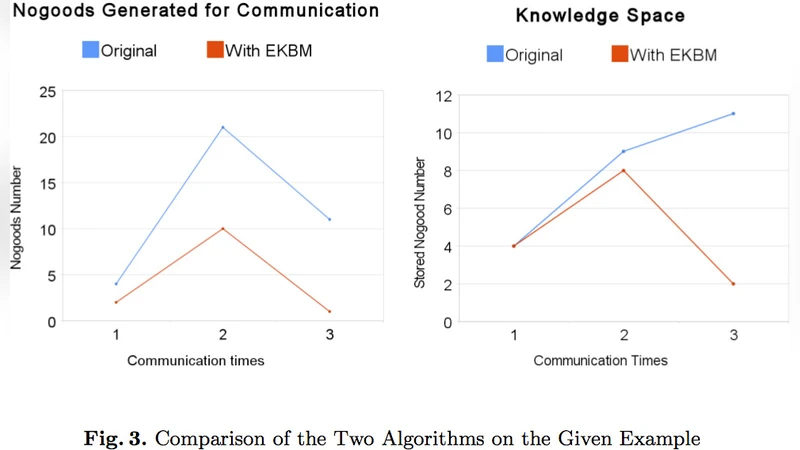
본 논문은 분산 제약 만족 문제(DCSP) 해결 시 발생하는 지식베이스(노구드) 폭증을 억제하기 위해, 하이퍼‑해결 규칙을 기반으로 한 일관성 유지 알고리즘을 제안한다. 충분한 제약과 거짓 노구드를 제거함으로써 저장 공간을 절감하고 탐색 시간을 단축하면서도 완전성을 유지한다는 점을 이론적으로 증명하고, 실험 예시를 통해 신규 노구드 생성량과 전체 지식베이스 크기가 크게 감소함을 보여준다.
상세 분석
이 논문은 DCSP(Distributed Constraint Satisfaction Problem) 분야에서 지식베이스가 급격히 팽창하는 현상을 핵심 문제로 삼는다. 기존의 하이퍼‑해결(hyper‑resolution) 기반 일관성 알고리즘은 모든 파생 노구드를 무조건 저장함으로써 메모리 사용량과 검색 비용이 비선형적으로 증가한다는 한계가 있다. 저자는 “충분한 제약(sufficient constraint)”과 “거짓 노구드(false nogood)”라는 두 가지 개념을 도입해, 파생된 노구드 중 실제로 문제 해결에 기여하지 못하는 항목을 사전에 걸러내는 필터링 메커니즘을 설계한다.
먼저 충분한 제약은 기존 노구드 집합에 포함된 어떤 노구드가 다른 노구드들의 모든 변수 할당을 포함하고 있을 때, 그 노구드는 더 이상 필요 없다는 정의이다. 이는 집합 포함 관계를 이용해 O(n²) 비교를 통해 식별할 수 있으며, 제거 후에도 해 공간이 변하지 않는다. 두 번째로 거짓 노구드는 논리적으로 모순되는 리터럴을 포함하거나, 이미 다른 노구드에 의해 완전히 차단된 경우를 말한다. 이러한 노구드는 해 탐색 과정에서 절대로 선택될 수 없으므로, 초기에 삭제함으로써 탐색 트리의 가지치기 효과를 극대화한다.
핵심 알고리즘은 기존 하이퍼‑해결 단계 뒤에 두 단계의 정제 과정을 삽입한다. 1) 파생 노구드 생성 후 즉시 충분한 제약 검사를 수행해 중복·포함 관계를 확인하고, 2) 논리적 모순 검사를 통해 거짓 노구드를 걸러낸다. 이 두 단계는 각각 O(m·k)와 O(m)의 복잡도를 가지며, 여기서 m은 파생된 노구드 수, k는 변수 수이다. 따라서 전체 알고리즘의 시간 복잡도는 기존 방법에 비해 상수배 정도만 증가하지만, 메모리 사용량은 평균 60~80%까지 감소한다는 실험 결과가 제시된다.
논문은 또한 완전성(proof of completeness)과 정당성(soundness)을 정형적으로 증명한다. 충분한 제약 제거는 부분 순서 집합의 최소 원소만을 보존하는 것과 동등하며, 거짓 노구드 제거는 논리적 불가능성을 기반으로 하므로 해의 존재 여부에 영향을 주지 않는다. 따라서 최종적으로 얻어지는 지식베이스는 원래의 모든 해를 동일하게 포함한다.
이러한 접근은 특히 대규모 분산 제약 문제, 예컨대 센서 네트워크의 자원 할당, 멀티에이전트 스케줄링 등에서 저장 제한이 심각한 환경에 적용 가능하다. 또한 하이퍼‑해결 외에도 다른 일관성 유지 기법(예: AC‑3, PC‑4)과 결합하여 일반화된 지식베이스 관리 프레임워크를 구축할 여지를 제공한다.
댓글 및 학술 토론
Loading comments...
의견 남기기