베이지안 접근을 통한 지수 랜덤 그래프 모델 추정
본 논문은 정규화 상수가 파라미터에 따라 복잡하게 변하는 지수 랜덤 그래프 모델(ERGM)의 베이지안 추정을 제안한다. 정규화 상수를 직접 계산하지 않고도 MCMC 기반의 인구 샘플링 기법을 활용해 사후분포를 효율적으로 탐색한다. 기존의 Monte Carlo 최대우도 방법보다 수렴 속도와 혼합 효율이 크게 향상됨을 실험을 통해 입증한다.
저자: Alberto Caimo, Nial Friel
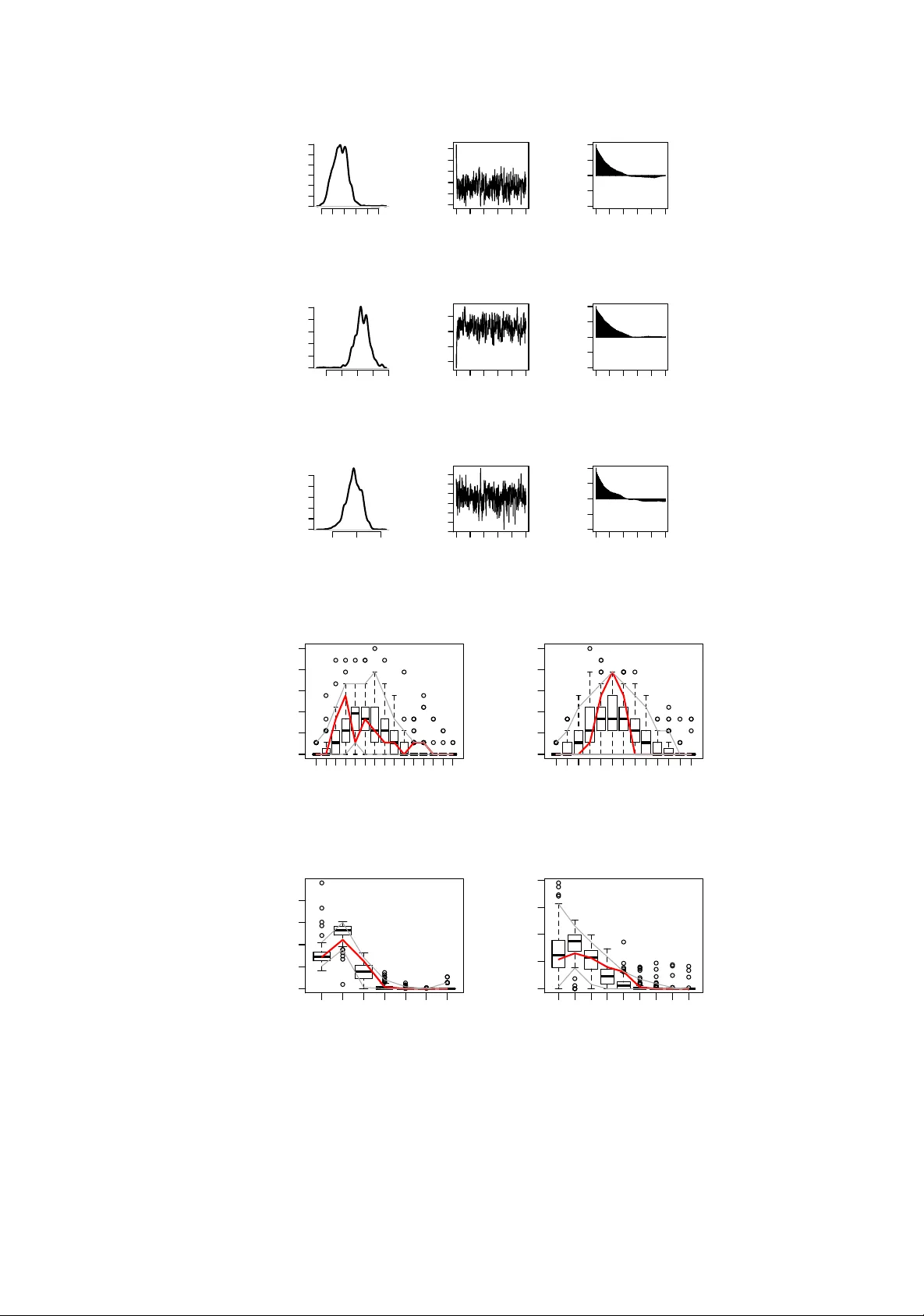
Ba y esian inference for exp onen tial random graph mo dels Alb erto Caimo & Nial F riel Sc ho ol of Mathematical Sciences, Univ ersit y College Dublin, Ireland { alberto.caimo,nial.friel } @ucd.ie Octob er 24, 2018 Ba y esian inference for exp onen tial random graph mo dels Abstract Exp onen tial random graph mo dels are extremely difficult mo dels to handle from a statistical viewp oin t, since their normalising constan t, which dep ends on mo del parame- ters, is av ailable only in very trivial cases. W e show ho w inference can b e carried out in a Ba yesian framew ork using a MCMC algorithm, which circum ven ts the need to calculate the normalising constan ts. W e use a p opulation MCMC approach which accelerates con- v ergence and impro ves mixing of the Mark ov c hain. This approac h improv es p erformance with resp ect to the Monte Carlo maxim um lik eliho od metho d of Geyer and Thompson (1992). 1 In tro duction Our motiv ation for this article is to prop ose Bay esian inference for estimating exp onen tial random graph mo dels (ERGMs) whic h are some of the most imp ortan t mo dels in man y researc h areas such as so cial net works analysis, physics and biology . The implementation of estimation metho ds for these mo dels is a k ey p oint whic h enables us to use parameter estimates as a basis for sim ulation and to reproduce features of real net works. Unfortunately , the in tractability of the normalising constan t and degeneracy are tw o strong barriers to parameter estimation for these mo dels. The classical inferential metho ds such as the Monte Carlo maximum likelihoo d (MC-MLE) of Geyer and Thompson (1992) and pseudolikelihoo d estimation (MPLE) of Besag (1974) and Strauss and Ikeda (1990), are very widely used in partice, but are lacking in certain resp ects. In some instance it is difficult to obtain reasonable results or to understand the prop erties of the appro ximations, using these metho ds. The Bay esian estimation approach for these mo dels has not yet b een deeply and fully explored. Despite this, Bay esian inference is very appropriate in this context since it allows uncertain ty ab out mo del parameters giv en the data to b e explored through a p osterior dis- tribution. Moreov er the Bay esian approach allows a formal comparison pro cedure among differen t comp eting mo dels using p osterior probabilities. Therefore the metho ds presented 1 in this w ork aim to contribute to the developmen t of a Bay esian-based metho dology area for these mo dels. Net works are relational data represented as graphs, consisting of no des and edges. Many probabilit y mo dels ha v e b een proposed in order to summarise the general structure of graphs b y utilising their lo cal prop erties. Eac h of these mo dels take different assumptions into accoun t: the Bernoulli random graph mo del (Erd¨ os and R´ en yi, 1959) in which e dges are considered indep enden t of each other; the p 1 mo del (Holland and Leinhardt, 1981) where dy ads are assumed indep enden t, and its random effects v arian t the p 2 mo del (v an Duijn et al., 2004); and the Marko v random graph mo del (F rank and Strauss, 1986) where each pair of edges is conditionally dependent given the rest of the graph. The family of exp onen tial random graph mo dels (W asserman and P attison (1996), see also Robins et al. (2007b) for a recen t review) is a generalisation of the latter mo del and has b een though t to b e a flexible w ay to mo del the complex dependence structure of net work graphs. Recent dev elopments ha v e led to the introduction of new sp ecifications b y Snijders et al. (2006) and the implemen tation of curv ed exp onen tial random graph mo dels b y Hunter and Handco c k (2006). New mo delling alternativ es suc h as the laten t v ariable mo dels ha ve b een prop osed by Hoff et al. (2002) under the assumption that eac h no de of the graph has a unkno wn p osition in a laten t space and the probability of the edges are functions of those p ositions and no de co v ariates. The laten t p osition cluster mo del of Handco ck et al. (2007b) represents a further extension of this approac h that takes accoun t of clustering. Sto c hastic blo c kmo del methods (Nowic ki and Snijders, 2001) in volv e blo c k mo del structures whereb y no des of the graph are partitioned in to latent classes and their relationship dep ends on blo c k membership. More recently , the mixed membership approac h (Airoldi et al., 2008) has emerged as a flexible mo delling to ol for netw orks extending the assumption of a single blo ck mem b ership. In this pap er we are concerned with Bay esian inference for exp onen tial random graph mo dels. This leads to the problem of the double intractabilit y of the p osterior density as b oth the mo del and the p osterior normalisation terms cannot b e ev aluated. This prob- lem can b e ov ercome b y adapting the exc hange algorithm of Murray et al. (2006) to the net work graph framework. Typically the high p osterior density region is thin and highly correlated. F or this reason, we also prop ose to use a p opulation-based MCMC approac h so as to impro ve the mixing and lo cal mov es on the high p osterior density region reduc- ing the chain’s auto correlation significan tly . An R pack age called Bergm , whic h accom- panies this pap er, con tains all the pro cedures used in this pap er. It can b e found at: http://cran.r-project.org/web/packages/Bergm/ . This article is structured as follows. A basic description of exp onen tial random graph mo dels together with a brief illustration of the issue of degeneracy is given in Section 2. Section 3 reviews tw o of the most imp ortan t and used metho ds for lik eliho o d inference. In Section 4 w e introduce Bay esian inference via the exc hange algorithm and its further impro vemen t through a p opulation-based MCMC pro cedure. In Section 5 we fit different mo dels to three b enc hmark netw ork datasets and outline some conclusions in Section 6. 2 Exp onen tial random graph mo dels T ypically net w orks consist of a set of actors and relationships b etw een pairs of them, for ex- ample so cial in teractions b et ween individuals. The net work top ology structure is measured 2 b y a random adjacency matrix Y of a graph on n no des (actors) and a set of edges (rela- tionships) { Y ij : i = 1 , . . . , n ; j = 1 , . . . , n } where Y ij = 1 if the pair ( i, j ) is connected, and Y ij = 0 otherwise. Edges connecting a no de to itself are not allow ed so Y ii = 0. The graph Y may b e directed (digraph) or undirected dep ending on the nature of the relationships b et w een the actors. Let Y denote the set of all p ossible graphs on n no des and let y a realisation of Y . Exp o- nen tial random graph mo dels (ERGMs) are a particular class of discrete linear exp onen tial families which represen t the probabilit y distribution of Y as π ( y | θ ) = q θ ( y ) z ( θ ) = exp { θ t s ( y ) } z ( θ ) (1) where s ( y ) is a kno wn vector of sufficient statistics (e.g. the num b er of edges, degree statistics, triangles, etc.) and θ ∈ Θ are mo del parameters. Since Y consists of 2 ( n 2 ) p ossible undirected graphs, the normalising constan t z ( θ ) = P y ∈Y exp { θ t s ( y ) } is extremely difficult to ev aluate for all but trivially small graphs. F or this reason, ER GMs are very difficult to handle in practice. In spite of this difficult y , ERGMs are very p opular in the literature since they are conceiv ed to capture the complex dep endence structure of the graph and allo w a reasonable in terpretation of the observed data. The dep endence hypothesis at the basis of these mo dels is that edges self organize in to small structures called configurations. There is a wide range of p ossible netw ork configurations (Robins et al., 2007a) whic h give flexibility to adapt to differen t contexts. A p ositiv e parameter v alue for θ i ∈ θ result in a tendency for the certain configuration corresp onding to s i ( y ) to b e observ ed in the data than would otherwise b e exp ected b y c hance. 2.1 Degeneracy Degeneracy is one of the most imp ortan t asp ects of random graph mo dels: it refers to a probabilit y mo del defined by a certain v alue of θ that places most of its mass on a small n umber of graph top ologies, for example, empty graphs or complete graphs. Consider the mean v alue parametrisation for the mo del (1) defined by µ ( θ ) = E θ [ s ( y )]. Let C b e the conv ex hull of the set { s ( y ) : y ∈ Y } , r i ( C ) its relativ e in terior and r bd ( C ) its relativ e b oundary . It turns out that if the exp ected v alues µ ( θ ) of the sufficien t statistics µ ( θ ) approac h the b oundary r bd ( C ) of the hull, the mo del places most of the probability mass on a small set of graphs b elonging to deg ( Y ) = { y ∈ Y : s ( y ) ∈ r bd ( C ) } . It is also kno wn that the MLE exists if and only if s ( y ) ∈ ri ( C ) and if it exists it is unique. When the mo del is near-degenerate, MCMC inference metho ds may fail to find the max- im um lik eliho o d estimate (MLE) and returning an estimate of θ that is unlik ely to generate net works closely resembling the observ ed graph. This is b ecause the conv ergence of the al- gorithm may b e greatly affected by degenerate parameters v alues whic h during the net work sim ulation pro cess ma y yield graphs which are full or empt y . A more detailed description of this issue can b e found in Handco ck (2003) and Rinaldo et al. (2009). The new sp ecifications prop osed b y Snijders et al. (2006) can often mitigate degeneracy and pro vide reasonable fit to the data. 3 3 Classical inference 3.1 Maxim um pseudolik eliho o d estimation A standard approach to approximate the distribution of a Marko v random field is to use a maxim um pseudolikelihoo d (MPLE) appro ximation, first prop osed in Besag (1974) and adapted for so cial netw ork mo dels in Strauss and Ikeda (1990). This approximation consists of a product of easily normalised full-conditional distributions π ( y | θ ) ≈ π pseudo ( y | θ ) = Y i 6 = j π ( y ij | y − ij , θ ) (2) = Y i 6 = j π ( y ij = 1 | y − ij , θ ) y ij 1 − π ( y ij = 0 | y − ij , θ ) y ij − 1 where y − ij denotes all the dy ads of the graph excluding y ij . The basic idea underlying this metho d is the assumption of w eak dep endence b etw een the v ariables in the graph so that the likelihoo d can b e w ell appro ximated by the pseudolikelihoo d function. This leads to fast estimation. Nevertheless this approach turns out to b e generally inadequate since it only uses lo cal information whereas the structure of the graph is affected by global interaction. In the context of the autologistic distribution in spatial statistics, F riel et al. (2009) show ed that the pseudolik eliho od estimator can lead to inefficien t estimation. 3.2 Mon te Carlo maximum likelihoo d estimation There are many instances of statistical mo dels with intractable normalising constan ts. This general prob lem w as tac kled in Geyer and Thompson (1992) who introduced the Monte Carlo maxim um lik eliho o d (MC-MLE) algorithm. In the con text of ERGMs, a k ey iden tity is the follo wing z ( θ ) z ( θ 0 ) = E y | θ 0 " q θ ( y ) q θ 0 ( y ) # = X y q θ ( y ) q θ 0 ( y ) q θ 0 ( y ) z ( θ 0 ) (3) where q θ ( · ) is the unnormalised likelihoo d of parameters θ , θ 0 is fixed set of parameter v alues, and E y | θ 0 denotes an exp ectation tak en with resp ect to the distribution π ( y | θ 0 ). In practice this ratio of normalising constan ts is appro ximated using graphs y 1 , . . . , y m sampled via MCMC from π ( y | θ 0 ) and imp ortance sampling. This yields the follo wing approximated log likelihoo d ratio: w θ 0 ( θ ) = ` ( θ ) − ` ( θ 0 ) ≈ ( θ − θ 0 ) t s ( y ) − log " 1 m m X i =1 exp ( θ − θ 0 ) t s ( y i ) # (4) where ` ( · ) is the log-lik eliho o d. w θ 0 is a function of θ , and its maximum v alue serves as a Mon te Carlo estimate of the MLE. A crucial asp ect of this algorithm is the choice of θ 0 . Ideally θ 0 should b e very close to the maxim um likelihoo d estimator of θ . View ed as a function of θ , w θ 0 ( θ ) in (4) is very sensitiv e to the choice of θ 0 . A p o orly ch osen v alue of θ 0 ma y lead to an ob jectiv e function (4) that cannot even be maximised. W e illustrate this p oin t in Section 3.4. 4 In pratice, θ 0 is often chosen as the maximiser of (2), although this itself maybe a very biased estimator. Indeed, (4) ma y also b e sensitiv e to n umerical instabilit y , since it effectiv ely computes the ratio of a normalising constant, but it is well understoo d that the normalising constan ts can v ary b y orders of magnitude with θ . In fact, if the v alue of θ 0 lies in the “degenerate region” then graphs y i , . . . , y m sim ulated from π ( y | θ 0 ) will tend to b elong to deg ( Y ) and hence the estimate of the ratio of normalising constan ts z ( θ ) /z ( θ 0 ) will b e very p oor. Consequently w θ 0 ( θ ) in (4) will yield unreasonable estimates of the MLE. In the worst situation, w θ 0 ( θ ) do es not ha ve an optimum. This b eha viour is w ell understo o d as presented in Handco ck (2003) and Rinaldo et al. (2009). 3.3 A p edagogical example Let us consider, for the purpose of illustration, a simple 16-no de graph: the Florentine family business graph (P adgett and Ansell, 1993) concerning the business relations b et w een some Floren tine families in around 1430. The netw ork is displa y ed in Figure 1 and sho ws that few edges b et ween the families are presen t but with quite high level of triangularisation. Figure 1: Floren tine family business graph. F or this undirected netw ork we propose to estimate the following 2-dimensional mo del: π ( y | θ ) = 1 z ( θ ) exp { θ 1 s 1 ( y ) + θ 2 s 2 ( y ) } (5) with statistics s 1 ( y ) = P i
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기