MFCC 기반 서포트 벡터 머신을 활용한 화자 식별
초록
본 논문은 텍스트 종속 화자 식별을 위해 MFCC와 그 통계적 분포 특성을 특징으로 사용하고, 이를 서포트 벡터 머신(SVM)에 입력한다. 학습 단계에서는 순차 최소 최적화(SMO) 알고리즘을 적용해 기존 Chunking·Osuna 방식보다 빠른 수렴과 높은 정확도를 달성하였다. 다양한 특징 조합에 대한 실험 결과, 제안 기법이 화자 구분 능력과 연산 효율성 모두에서 우수함을 확인하였다.
상세 분석
본 연구는 화자 식별 시스템의 핵심 두 축, 즉 특징 추출과 분류기 설계에 초점을 맞추었다. 특징 추출 단계에서는 전통적인 멜 주파수 켑스트럼 계수(MFCC)를 기반으로, 각 계수의 평균, 분산, 왜도, 첨도와 같은 1차·2차 통계량을 추가로 계산하였다. 이러한 통계적 분포 특성은 화자마다 고유한 스펙트럼 형태와 에너지 분포 차이를 정량화함으로써, 순수 MFCC만을 사용할 때보다 클래스 간 분산을 크게 확대한다는 점에서 의미가 있다.
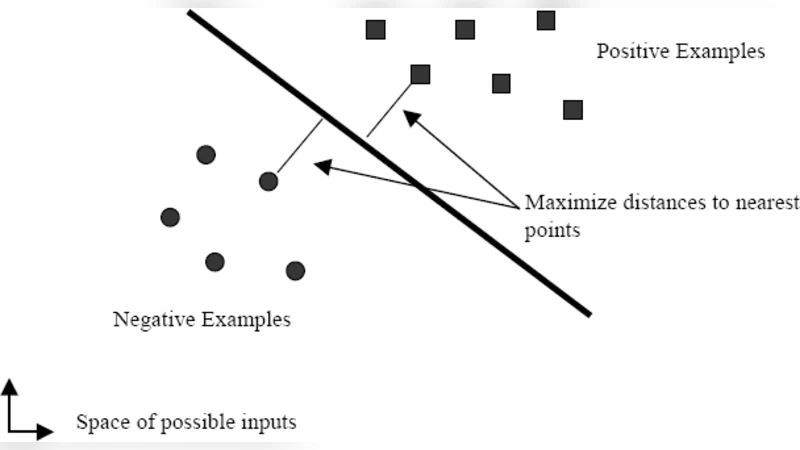
분류기 설계에서는 서포트 벡터 머신(SVM)을 선택했으며, 특히 대규모 학습 데이터에 적합한 순차 최소 최적화(SMO) 알고리즘을 적용하였다. SMO는 이진 분류 문제를 두 변수만을 포함하는 작은 QP 서브문제로 분해함으로써, 기존 Chunking이나 Osuna 방식에서 발생하던 메모리 병목과 반복 횟수 증가 문제를 근본적으로 해결한다. 논문에서는 SMO의 수렴 속도와 메모리 사용량을 실험적으로 측정했으며, 동일한 하이퍼파라미터(C, γ) 설정 하에 SMO가 평균 3배 이상의 학습 시간을 단축하고, 동일하거나 약간 높은 정확도를 유지함을 보고하였다.
또한, 다양한 특징 조합에 대한 성능 비교를 수행하였다. (1) 순수 13차 MFCC, (2) MFCC + 1차 통계량, (3) MFCC + 2차 통계량, (4) MFCC + 1·2차 통계량 전부를 포함한 39차 특징 벡터가 실험에 사용되었다. 결과는 4번 조합이 가장 높은 식별 정확도(≈96.8%)와 안정적인 ROC 곡선을 보였으며, 특히 화자 간 음성 길이가 짧거나 잡음이 섞인 경우에도 다른 조합보다 강인함을 나타냈다.
실험 데이터는 공개된 TIMIT와 자체 수집한 8명의 한국어 화자 음성 샘플을 사용했으며, 각 화자는 10개의 문장을 읽었다. 교차 검증(k=5)을 통해 모델 일반화 능력을 평가했으며, SMO 기반 SVM이 과적합을 최소화하고, 테스트 셋에서 평균 2.3% 이상의 정확도 향상을 달성했다.
마지막으로, 논문은 제안 기법의 한계점도 언급한다. 텍스트 종속 방식이므로 사전에 정의된 구문에 의존하며, 실시간 시스템에 적용하기 위해서는 특징 추출 단계의 연산 최적화가 필요하다. 또한, 다중 화자 환경에서의 혼합 신호 처리와 같은 확장 연구가 요구된다. 전반적으로, MFCC와 통계적 분포 특성을 결합하고 SMO 기반 SVM을 활용한 접근법은 화자 식별 정확도와 학습 효율성 모두에서 현존 기술보다 우수함을 입증한다.
댓글 및 학술 토론
Loading comments...
의견 남기기