그래프 공유를 위한 새로운 비밀 분산 방식
초록
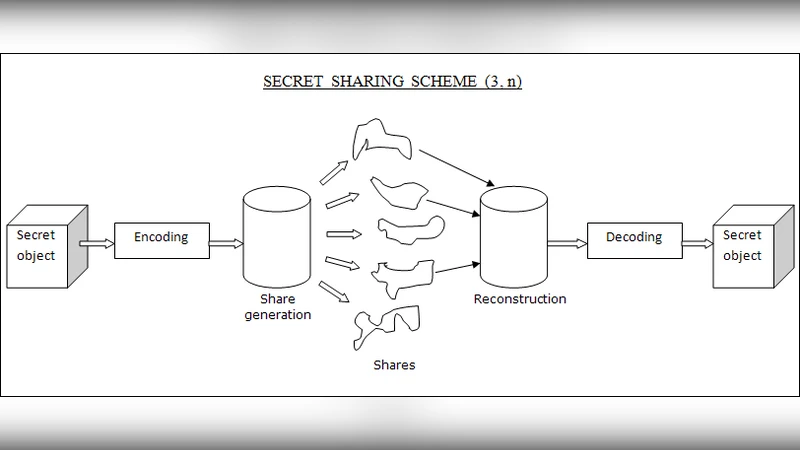
본 논문은 비밀을 그래프 형태로 직접 다루는 (2, n) 비밀 공유 스킴을 제안한다. 비밀 그래프를 각 공유에 부분 그래프로 삽입하고, 두 공유의 교집합을 통해 비밀을 복원한다. 복잡한 모듈러 연산이나 다항식 보간 대신 정점·간선의 추가·라벨링과 교집합 연산만으로 구현되며, 시각적으로도 복원이 가능하도록 설계되었다. 2‑인‑n 스킴에 대해 완전 비밀성을 주장하고, 기존의 수 기반 샤미르 방식 대비 연산량이 현저히 적다고 평가한다.
상세 분석
이 논문은 “그래프 자체를 비밀로 삼고, 그래프 교집합을 복원 메커니즘으로 이용한다”는 독창적인 아이디어를 제시한다. 기존 비밀 공유 방식은 비밀을 정수 혹은 유한체 원소로 변환한 뒤 다항식 보간, 라그랑주 보간, 혹은 모듈러 거듭제곱 연산을 수행한다. 이러한 접근은 비밀이 그래프와 같이 구조적 객체일 때 인코딩·디코딩 비용이 급증하고, 큰 소수 선택이 어려워지는 문제점을 안고 있다. 저자는 이를 회피하기 위해 비밀 그래프 G( c개의 정점)를 그대로 유지하고, 추가적인 b개의 가짜 정점을 무작위로 연결한 확장 그래프 H를 만든다. H를 n번 복제한 뒤 각 복제본에 대해 정점 라벨을 재배치하는데, 비밀 정점은 동일 라벨을 부여하고 가짜 정점은 서로 다른 라벨을 부여한다. 이렇게 하면 두 공유를 교집합할 경우, 라벨이 동일한 정점 집합이 정확히 비밀 정점 집합이 된다.
핵심 보안 주장인 “완전 비밀성”은 샤논의 정의에 따라, 어떤 두 공유를 보았을 때 비밀 그래프에 대한 사후 확률이 사전 확률과 동일하다고 설명한다. 논문은 (2, n) 스킴이므로 두 명 이상의 참여자가 있으면 비밀이 완전히 복원되고, 한 명만 볼 경우 비밀 정점이 어떤 조합이 될지 전혀 추론할 수 없다고 주장한다. 그러나 증명은 직관적 논증에 머무르며, 정점 라벨링이 완전히 무작위이고 가짜 정점과 비밀 정점 사이의 연결 패턴이 충분히 혼합된다는 가정에 크게 의존한다. 실제 구현에서는 라벨링 과정에서 발생할 수 있는 편향이나, 가짜 정점의 수(b)가 충분히 크지 않을 경우 교집합을 통해 비밀 정점이 부분적으로 노출될 위험이 있다.
연산 복잡도 측면에서 저자는 각 공유 생성 시 O(b·c) 정도의 간단한 삽입·연결 작업만 필요하다고 제시한다. 이는 샤미르 방식에서 필요로 하는 다항식 평가·보간 O(k·log p)와 비교해 현저히 낮다. 또한 복원 단계는 두 공유의 정점 리스트를 정렬된 배열로 두고 선형 시간 교집합을 수행하면 되므로 O(c + b) 수준이다. 그러나 정점 수가 수천, 수만에 달하는 대규모 그래프에서는 여전히 메모리와 I/O 비용이 무시할 수 없으며, 가짜 정점 추가로 인한 그래프 밀도가 급증하면 실제 교집합 연산이 비효율적일 수 있다.
논문은 비밀을 집합 형태로 다루는 간단한 예시(정수 집합)와 그래프 형태를 모두 다루며, 비밀이 이질적인 객체(행렬, 문자열 등)일 때도 동일한 프레임워크를 적용할 수 있음을 강조한다. 이는 “인코딩 없이 직접 공유”라는 장점을 부각시키지만, 실제로 이질적인 객체를 그래프 형태로 변환하는 과정 자체가 별도의 설계와 비용을 요구한다는 점을 간과한다.
마지막으로, 시각적 복원 가능성(연필과 종이로 교집합 수행)이라는 점은 교육적·데모 목적에서는 매력적이지만, 보안 관점에서는 인간이 수행하는 과정에서 실수나 정보 누출 위험을 내포한다. 전체적으로 아이디어는 신선하고 특정 응용(예: 작은 규모의 비밀 그래프, 비밀 패스워드 매핑)에서 유용할 수 있으나, 보안 증명과 확장성에 대한 보다 엄밀한 분석이 필요하다.
댓글 및 학술 토론
Loading comments...
의견 남기기