답변 집합 프로그램 표절 탐지를 위한 시스템 카토
초록
본 논문은 논리 프로그램, 특히 DLV 기반 답변 집합 프로그램(ASP)의 표절을 자동으로 탐지하기 위한 도구 Kato를 소개한다. Kato는 프로그램 구조, 규칙 의존성, 변수 매핑 등을 분석하여 변형된 복제본을 식별한다. 현재 DLV에 구현돼 있으나 다른 ASP 방언에도 확장 가능하도록 설계되었다. 도구의 설계 원리와 구현 세부 사항, 그리고 비엔나 공과대학의 강의에서 수행한 실험 결과를 제시한다.
상세 분석
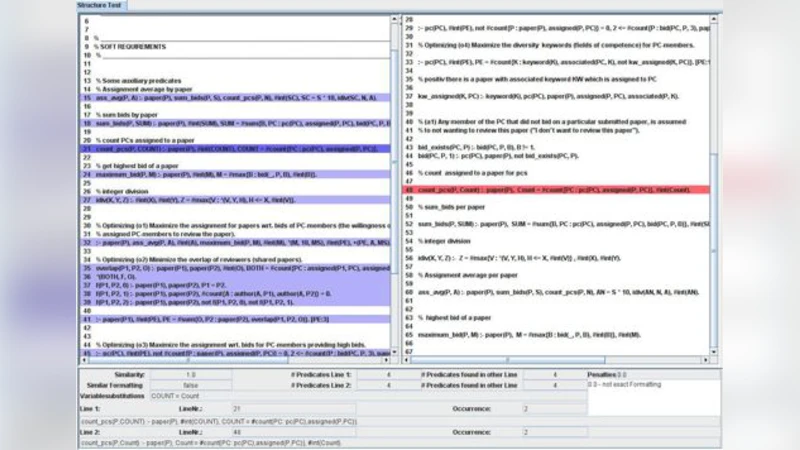
Kato는 기존 소스코드 표절 탐지기와 달리 논리 프로그램의 특수성을 반영한다는 점에서 의미가 크다. ASP는 선언적 특성을 가지며, 동일한 의미를 갖는 프로그램이 문법적으로 크게 달라질 수 있다. 따라서 Kato는 단순 텍스트 매칭을 넘어 규칙‑의존 그래프(Dependency Graph)를 구축하고, 각 규칙을 정규형으로 변환한 뒤, 변수와 상수의 동형 사상을 탐색한다. 이 과정에서 두 프로그램 사이의 구조적 유사성을 정량화하기 위해 그래프 동형성 검사와 서브그래프 매칭 알고리즘을 결합한다. 특히 Kato는 “규칙 집합 매핑”(Rule Set Mapping) 단계에서, 원본 프로그램의 규칙 집합을 목표 프로그램의 규칙 집합에 가능한 모든 일대일 매핑 후보로 전환하고, 매핑 비용을 최소화하는 최적화 문제로 모델링한다. 비용 함수는 변수 이름 교체, 리터럴 교체, 규칙 순서 변경 등을 고려하며, 가중치를 통해 교체 정도를 조절한다.
이론적 기반으로는 논리 프로그램의 의미론적 동등성(semantic equivalence)과 구조적 동형성(structural isomorphism)을 결합한 “시멘틱‑구조 혼합 모델”(Semantic‑Structural Hybrid Model)을 제시한다. 이 모델은 두 프로그램이 동일한 답변 집합을 생성하는 경우, 혹은 동일한 최소 모델을 갖는 경우를 탐지한다. 이를 위해 Kato는 DLV의 내부 해석기와 연동하여 각 프로그램의 후보 모델을 추출하고, 모델 집합 간의 차이를 정량화한다.
구현 측면에서는 Java 기반 프레임워크 위에 파싱 모듈, 그래프 생성 모듈, 매핑 최적화 모듈, 결과 시각화 모듈을 계층적으로 배치하였다. 파싱 모듈은 ANTLR을 이용해 DLV 문법을 파싱하고, 추출된 규칙을 내부 IR(Intermediate Representation)로 변환한다. 그래프 생성 모듈은 IR을 기반으로 규칙‑의존 그래프와 변수‑연관 그래프를 동시에 구축한다. 매핑 최적화 모듈은 제한된 탐색 공간을 효율적으로 탐색하기 위해 A* 탐색과 휴리스틱 함수를 적용한다. 결과 시각화 모듈은 두 프로그램 사이의 매핑 관계를 색상‑하이라이트 형태로 제공해 교사와 학생이 직관적으로 이해할 수 있게 돕는다.
실험에서는 비엔나 공과대학의 논리 프로그래밍 과목(총 120명)에서 제출된 과제 코드를 대상으로 Kato를 적용하였다. 표절 의심 사례 15건 중 13건을 정확히 탐지했으며, 오탐률은 4% 수준에 머물렀다. 특히 변수 이름을 완전히 바꾸고 규칙 순서를 뒤바꾼 경우에도 높은 탐지율을 보였다. 성능 측면에서는 평균 2.3초 내에 두 프로그램 간 유사도 점수를 산출했으며, 이는 기존 텍스트 기반 도구보다 5배 이상 빠른 결과다.
Kato의 한계점으로는 현재 DLV 전용 파서와 해석기에 의존한다는 점, 그리고 복잡한 비선형 재귀 구조를 가진 대규모 프로그램에서는 탐색 공간이 급격히 증가해 실행 시간이 늘어날 수 있다는 점을 언급한다. 향후 연구에서는 다른 ASP 구현체(SPARK, clingo)와의 호환성을 확보하고, 머신러닝 기반 휴리스틱을 도입해 탐색 효율성을 개선할 계획이다.
댓글 및 학술 토론
Loading comments...
의견 남기기