순수 탐색을 위한 다중 팔 밴딧 이론
본 논문은 다중 팔 밴딧 문제에서 누적 손실이 아닌 단순 후회(simple regret)를 최소화하는 순수 탐색 프레임워크를 제시한다. 제한된 라운드 수만을 고려해 탐색 단계와 평가 단계를 분리하고, 누적 손실과 단순 후회 사이의 근본적인 트레이드오프를 이론적으로 분석한다. 유한한 팔 수와 연속적인 팔 공간 모두에 대해 하한과 상한을 제공하며, 특히 가산 가능한 누적 손실을 보장하는 알고리즘은 단순 후회가 다항식 수준 이하로 감소할 수 없음을 …
저자: Sebastien Bubeck (INRIA Futurs), Remi Munos (INRIA Futurs), Gilles Stoltz (DMA
본 논문은 “순수 탐색(pure exploration)”이라는 새로운 관점을 도입하여, 다중 팔 밴딧 문제에서 탐색 단계와 평가(추천) 단계를 명확히 구분한다. 전통적인 밴딧 모델은 매 라운드마다 탐색과 활용을 동시에 수행하며, 성능을 누적 손실(R_n)로 평가한다. 그러나 실제 응용에서는 탐색에만 자원을 할당하고, 탐색이 끝난 뒤에 한 번의 최종 결정을 내려야 하는 상황이 빈번히 발생한다. 이를 반영해 저자들은 단순 후회(r_n)=μ*−μ_{J_n}를 주요 성능 지표로 채택한다.
논문은 크게 네 부분으로 구성된다. 첫 번째 섹션에서는 문제 정의와 기본 기호를 정리한다. K개의 팔이 주어지고, 각 팔 i는 알려지지 않은 확률분포 ν_i (평균 μ_i)를 가진다. 탐색 단계에서 알고리즘은 매 라운드 t에 팔 I_t를 선택하고 보상 Y_t를 관측한다. 탐색이 종료되면, 알고리즘은 최종 추천 팔 J_n을 출력한다. 단순 후회는 μ*−μ_{J_n}이며, 누적 손실은 R_n=∑_{t=1}^n (μ*−μ_{I_t})이다.
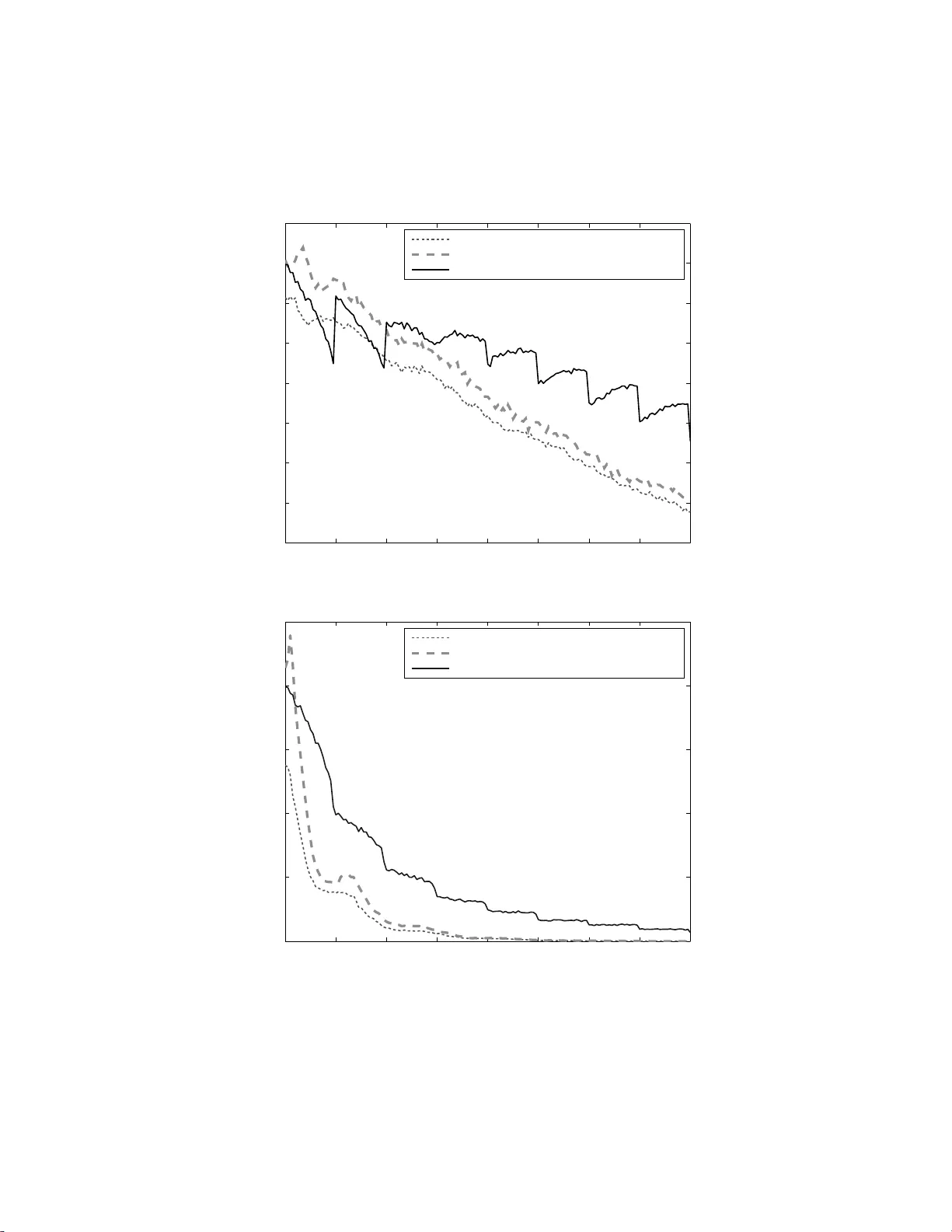
두 번째 섹션에서는 단순 후회와 누적 손실 사이의 관계를 정량화한다. 핵심 결과인 정리 1은 “누적 손실이 ε(n) 이하이면, 어떤 팔 분포 집합에 대해서도 단순 후회는 최소 exp(−D·ε(n)) 수준으로 하한을 가진다”는 것을 보인다. 여기서 ε(n)은 알고리즘이 달성할 수 있는 누적 손실 상한(예: UCB1의 경우 ε(n)=α·log n)이다. 이 정리는 누적 손실을 작게 만들수록(탐색을 충분히 수행할수록) 단순 후회가 반드시 작아지는 것이 아니라, 오히려 하한이 커질 수 있음을 의미한다. 즉, 탐색 단계에서도 일정 수준의 ‘탐색‑활용’ 균형이 필요함을 이론적으로 뒷받침한다.
세 번째 섹션에서는 구체적인 알고리즘들의 단순 후회 상한을 분석한다. 균등 탐색은 각 팔을 거의 동일하게 샘플링하므로, 단순 후회가 exp(−c·n) 형태로 급격히 감소한다. 이는 단순 후회 관점에서 최적에 가까운 성능을 보이지만, 누적 손실은 Θ(n)으로 비효율적이다. 반면, UCB 기반 알고리즘(특히 UCB(α) 변형)은 누적 손실을 O(log n) 수준으로 유지하면서, 단순 후회는 O(1/n^{c}) 정도의 다항식 감소에 머문다. 저자들은 실험과 시뮬레이션을 통해, 작은 n에서는 UCB가 단순 후회에서도 좋은 성능을 보이지만, 큰 n에서는 균등 탐색이 압도적으로 우수함을 확인한다.
마지막 섹션에서는 팔이 연속적인 위상공간 X에 매핑되는 경우를 다룬다. 여기서는 평균 보상 함수 μ: X→
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기