LHC 그리드 데이터베이스: 성과와 남은 과제
초록
본 논문은 LHC 실험에서 그리드 환경에 구축된 관계형 데이터베이스 시스템의 현황을 정리한다. 조건·보정 데이터의 저장·배포·접근 방식을 실험별로 비교하고, 대규모 재구성 및 분석 워크플로우에서 나타난 확장성 문제와 해결책을 제시한다. 또한 아직 해결되지 않은 성능·보안·운영 이슈를 조명한다.
상세 분석
LHC 실험은 매초 수백 테라바이트에 달하는 이벤트 데이터를 생산하지만, 이 데이터를 올바르게 재구성하고 물리 분석에 활용하려면 ‘비이벤트 데이터’—즉, 검출기 상태, 교정 상수, 정렬 파라미터 등—가 반드시 필요하다. 이러한 비이벤트 데이터는 전통적인 파일 기반 시스템이 아니라 관계형 데이터베이스(RDBMS)에 저장되며, 그리드 컴퓨팅 노드가 실시간으로 조회한다. 논문은 ATLAS, CMS, ALICE, LHCb 네 실험이 각각 선택한 DBMS(MySQL, Oracle, PostgreSQL 등)와 그 이유를 상세히 분석한다.
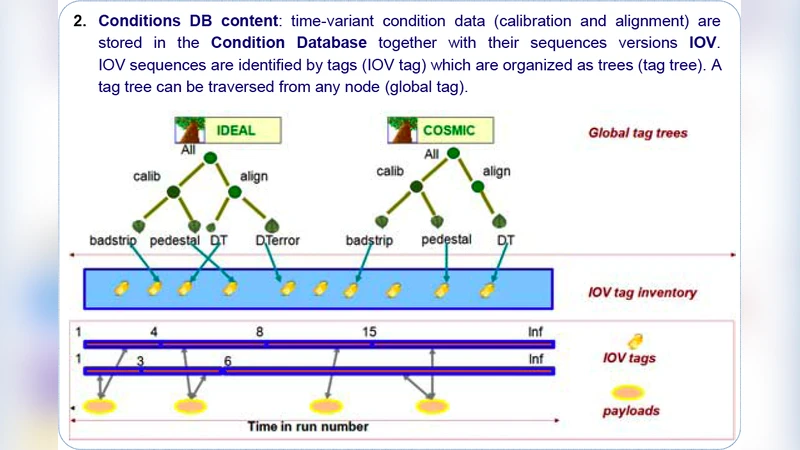
첫 번째 핵심은 데이터 모델링이다. 조건 데이터는 ‘시간 구간(Interval of Validity, IOV)’에 따라 버전 관리되며, 이는 복합 키와 히스토리 테이블을 이용해 구현된다. 두 번째는 데이터 배포 메커니즘으로, CMS는 Frontier/Squid 캐시 프록시 체인을, ATLAS는 COOL/COOLDB와 Oracle RAC를 활용해 전 세계 100여 개 사이트에 복제한다. 이러한 구조는 읽기 전용 워크로드에 최적화돼 있지만, 데이터 업데이트(예: 매일 새로 측정된 교정 상수) 시 동기화 지연이 발생한다.
세 번째는 접근 패턴 분석이다. 재구성 단계에서는 수천 개의 작업이 동시에 동일한 IOV 범위의 데이터를 조회해 ‘읽기 폭주’ 현상이 나타난다. 이를 완화하기 위해 CMS는 HTTP 기반 캐시(Frontier)와 다중 레이어 프록시를 도입했으며, ATLAS는 데이터베이스 파티셔닝과 로드밸런싱을 적용했다. 그러나 캐시 적중률이 낮은 경우 네트워크 대역폭과 DB 서버 부하가 급증해 작업 지연이 발생한다.
네 번째로는 확장성 테스트 결과가 제시된다. 10 k CPU 규모의 대규모 재구성에서 Oracle RAC는 1 TB·월 규모의 조건 데이터에 대해 평균 응답시간 120 ms를 유지했지만, 피크 시 300 ms를 초과했다. MySQL 기반 시스템은 비용 효율성이 높지만, 동시 연결 수가 5 k 이상일 때 커넥션 풀 관리가 병목이 된다.
마지막으로 남은 과제는 세 가지로 요약된다. (1) 실시간 업데이트와 대규모 읽기 워크로드를 동시에 만족시키는 하이브리드 아키텍처 설계, (2) 전 세계 분산 캐시 일관성 유지와 캐시 적중률 향상을 위한 프로토콜 표준화, (3) 데이터베이스 운영 자동화와 장애 복구를 위한 AI 기반 모니터링 도입이다. 이러한 문제들은 향후 HL‑LHC와 같은 초대형 실험에서도 핵심 과제로 남는다.
댓글 및 학술 토론
Loading comments...
의견 남기기