전역 맥락 서비스 구현을 위한 활성 아키텍처
초록
본 논문은 언제 어디서나 이용 가능한 전역 퍼베이시 서비스 제공을 위해, 사용자 이벤트와 다양한 데이터 소스를 실시간으로 매칭하는 분산 매칭 서비스를 설계한다. 피어‑투‑피어 네트워크를 활용해 데이터와 서비스 배포를 동적으로 관리하고, 확장성·관리성·점진적 진화를 지원하는 아키텍처를 제안한다.
상세 분석
이 논문은 “퍼베이시(contextual) 서비스”라는 개념을 “어디서든, 언제든, 모든 클라이언트에게 제공되는 서비스”로 정의하고, 이를 실현하기 위한 핵심 인프라스트럭처로 ‘매칭 서비스’를 제시한다. 매칭 서비스는 다수의 이질적인 데이터 스트림(센서, 사용자 입력, 외부 웹 서비스 등)을 수집·통합하고, 사전 정의된 복합 규칙에 따라 실시간으로 의미 있는 이벤트를 도출한다. 이러한 기능을 전 세계 규모로 제공하려면 네트워크 지연, 데이터 포맷 다양성, 서비스 진화 등 복합적인 제약을 동시에 만족시켜야 한다.
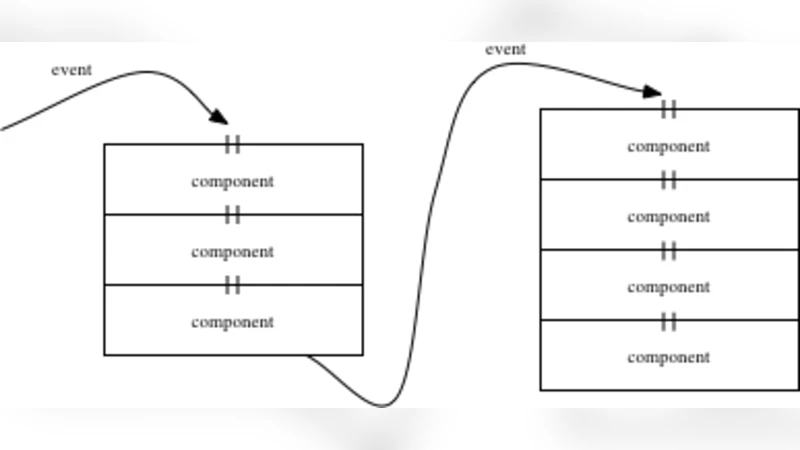
저자들은 전통적인 중앙집중식 아키텍처가 단일 장애점과 확장성 한계에 빠진다는 점을 지적하고, 피어‑투‑피어(P2P) 기반의 분산 토폴로지를 채택한다. P2P 네트워크는 노드 간에 데이터와 매칭 로직을 복제·분산함으로써 부하를 균등하게 분산시키고, 노드 추가·제거가 자유로운 ‘동적 토폴로지’를 가능하게 한다. 특히, ‘활성(active) 아키텍처’라는 용어를 도입해 매칭 로직 자체를 코드 조각(스니펫) 형태로 노드에 배포하고, 런타임에 필요에 따라 업데이트하거나 교체할 수 있게 설계한다. 이는 서비스가 새로운 데이터 포맷이나 규칙을 받아들일 때 전체 시스템을 중단하지 않고 점진적으로 진화할 수 있음을 의미한다.
스케일러빌리티를 확보하기 위해 저자들은 ‘데이터 파티셔닝’과 ‘쿼리 라우팅’ 메커니즘을 결합한다. 데이터 파티셔닝은 해시 기반 또는 지리적 클러스터링을 통해 관련 이벤트를 물리적으로 가까운 노드에 모으고, 쿼리 라우팅은 이벤트 흐름에 따라 가장 적합한 매칭 엔진으로 전달한다. 이를 통해 네트워크 트래픽을 최소화하고, 로컬 캐시 활용을 극대화한다. 또한, ‘서비스 디스커버리’ 프로토콜을 통해 새로운 매칭 모듈이 네트워크에 등장하면 자동으로 레지스트리에 등록되고, 기존 노드가 이를 인식해 즉시 활용한다.
관리 측면에서는 ‘모니터링·오케스트레이션 레이어’를 도입해 각 노드의 상태, 처리량, 지연 시간을 실시간으로 수집한다. 수집된 메트릭은 중앙 대시보드가 아니라 분산 로그 시스템에 저장되어, 장애 발생 시 로컬 복구 절차를 자동으로 트리거한다. 이와 동시에 ‘버전 관리’ 메커니즘을 통해 매칭 로직의 롤백·업그레이드가 안전하게 이루어지며, 테스트용 샌드박스 환경에서 새로운 규칙을 검증한 뒤 프로덕션에 적용한다.
결과적으로, 이 논문은 전역 퍼베이시 서비스가 요구하는 ‘실시간성·다양성·확장성·진화성’을 동시에 만족시키는 설계 원칙을 제시한다. P2P 기반의 활성 아키텍처는 기존 클라우드 중심 모델이 갖는 중앙 집중식 병목을 해소하고, 서비스 운영자가 지속적인 변화에 대응할 수 있는 유연성을 제공한다.
댓글 및 학술 토론
Loading comments...
의견 남기기