GPU에서 구현한 Heisenberg 스핀 글래스 모델: 신화와 실제
초록
본 논문은 3차원 Heisenberg 스핀 글래스 모델을 GPU에 구현하는 여러 방법을 비교한다. 공유 메모리를 이용한 구현이 전역 메모리만 사용하는 경우보다 성능이 우수한 것은 다중 히트(multi‑hit) 기법을 적용했을 때에만 나타난다는 실험 결과를 제시한다.
상세 분석
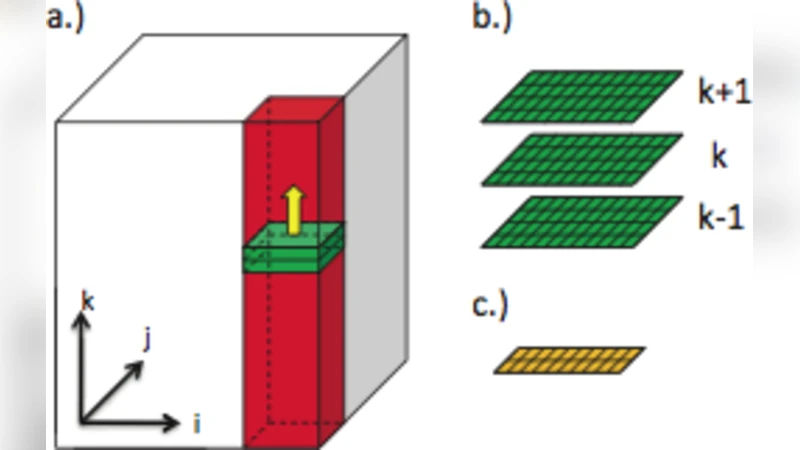
Heisenberg 스핀 글래스 모델은 각 격자점에 3차원 연속 스핀 벡터를 두고, 인접 스핀 사이의 무작위 결합 상수를 이용해 에너지를 정의한다. Monte Carlo 시뮬레이션, 특히 Metropolis 알고리즘이나 Heat‑Bath 업데이트는 대규모 격자에 대해 수억 번의 연산을 요구하므로 GPU와 같은 대량 병렬 처리 장치에 적합하다. 논문은 CUDA 기반 구현을 중심으로 세 가지 주요 메모리 전략을 검토한다. 첫째, 전역(Global) 메모리만을 사용해 스핀 배열과 결합 상수를 직접 읽고 쓰는 ‘베이직’ 구현이다. 둘째, 스핀 데이터를 블록 단위로 공유 메모리(Shared Memory)로 복사한 뒤, 블록 내부에서 여러 번 업데이트를 수행하는 ‘멀티‑히트’ 전략이다. 셋째, 텍스처 메모리와 상수 메모리를 활용해 읽기 전용 데이터를 캐시하는 혼합형 구현이다.
핵심 성능 병목은 메모리 대역폭과 레이턴시이며, 전역 메모리는 높은 대역폭에도 불구하고 접근 지연이 크다. 공유 메모리는 용량이 제한적이지만, 동일 블록 내 스레드가 반복적으로 같은 데이터를 재사용할 경우 레이턴시를 크게 감소시킨다. 논문은 ‘멀티‑히트’ 기법—즉, 한 번의 공유 메모리 로드 후 여러 Monte Carlo 스텝을 수행하는 방법—이 적용될 때만 공유 메모리의 이점이 실현된다고 강조한다. 이는 한 번 로드된 데이터를 여러 번 사용함으로써 전역 메모리 접근 횟수를 감소시키고, 연산 대비 메모리 전송 비율을 개선하기 때문이다.
또한, 스레드 블록 크기와 워프(warp) 정렬, 메모리 공동 접근(coalesced access) 여부가 성능에 미치는 영향을 정량적으로 분석한다. 블록 크기가 너무 작으면 공유 메모리 활용도가 낮아지고, 너무 크면 레지스터와 공유 메모리 사용량이 포화돼 SM(Streaming Multiprocessor)당 활성 스레드 수가 감소한다. 최적의 블록 크기는 128~256 스레드이며, 이는 CUDA 아키텍처의 메모리 대역폭과 연산 유닛을 균형 있게 활용한다.
결과적으로, 전역 메모리만을 이용한 구현은 단일 히트(한 번의 업데이트) 상황에서 가장 간단하고 오버헤드가 적지만, 멀티‑히트 상황에서는 공유 메모리 기반 구현이 1.52배 정도의 속도 향상을 보인다. 텍스처 메모리를 이용한 구현은 읽기 전용 결합 상수에 대해 약간의 이점을 제공하지만, 전체 성능에 미치는 영향은 제한적이다. 논문은 또한 GPU와 CPU 간의 성능 비교를 수행해, 동일한 격자 크기(예: 64³)에서 GPU가 2030배 빠른 실행 시간을 기록했음을 보고한다.
이러한 분석은 “GPU는 언제나 빠르다”는 일반적인 신화를 바로잡으며, 메모리 계층 구조와 알고리즘 특성에 맞는 최적화가 선행되지 않으면 기대 이하의 성능을 보일 수 있음을 경고한다. 특히, 공유 메모리의 장점을 살리기 위해서는 데이터 재사용을 극대화하는 멀티‑히트와 같은 기법이 필수적이다.
댓글 및 학술 토론
Loading comments...
의견 남기기