네트워크 숨겨진 속성에 대한 능동 학습
초록
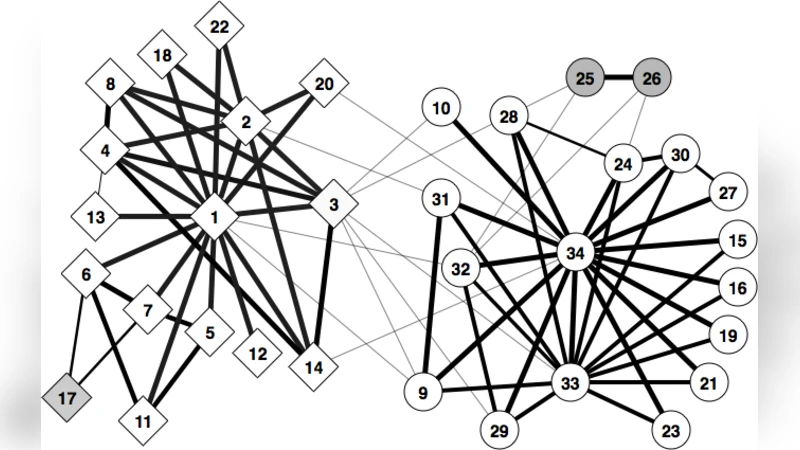
이 논문은 정점의 숨겨진 속성이 네트워크 구조와 상관관계가 있을 때, 속성을 비용 효율적으로 파악하기 위한 능동 학습 전략을 제시한다. 스토캐스틱 블록 모델을 가정하고, 정점 하나를 선택해 실제 속성을 질의할 때 두 가지 기준—상호 정보량 최대화와 조건부 깁스 분포의 두 독립 샘플 간 평균 일치도 최대화—을 사용한다. 실험 결과 두 방법 모두 단순 휴리스틱보다 뛰어나며, 특정 정점이 초기에 자주 선택되는 현상을 보인다.
상세 분석
본 연구는 네트워크에서 정점의 숨겨진 타입(속성)을 추정하는 문제를 능동 학습(active learning) 프레임워크로 재구성한다. 기본 가정은 네트워크가 스토캐스틱 블록 모델(SBM)로 생성된다는 것이며, 이는 정점 집단 간 연결 확률이 블록 행렬에 의해 정의된다는 의미다. 기존 연구들은 주로 블록 구조가 동질적(assortative)이라고 가정하거나, 사전 지식 없이 무작위 샘플링에 의존했지만, 이 논문은 동질성 여부에 관계없이 일반적인 SBM을 전제로 한다.
첫 번째 질의 전략은 ‘상호 정보량(mutual information, MI)’을 최대화하는 것이다. 구체적으로, 아직 관측되지 않은 정점들의 속성 분포와 후보 정점의 속성 사이의 MI를 계산하고, 그 값이 가장 큰 정점을 선택한다. MI는 정보 이론에서 두 변수 간 의존성을 정량화하는 표준 지표이며, 여기서는 조건부 확률분포 (P(\mathbf{t}_{-i}\mid G, t_i))와 사전 분포 (P(t_i\mid G))를 이용해 추정한다. 이 과정은 마르코프 체인 몬테카를로(MCMC) 샘플링을 통해 근사되며, 샘플링 비용이 크지만 정점 선택의 효율성을 크게 향상시킨다.
두 번째 전략은 ‘평균 일치도(average agreement, AA)’를 활용한다. 두 개의 독립적인 깁스 샘플 (\mathbf{t}^{(1)})와 (\mathbf{t}^{(2)})를 생성한 뒤, 후보 정점 i에 대해 두 샘플이 동일한 타입을 가질 확률을 계산하고, 그 확률이 높을수록 i를 질의한다. 이 방법은 MI와 달리 직접적인 엔트로피 계산을 피하고, 샘플 간 일치 정도만을 이용해 정점의 정보 가치를 평가한다. 실험에서는 AA가 MI와 비슷한 수준의 성능을 보이며, 구현이 비교적 간단하다는 장점이 있다.
실험은 두 가지 실제 네트워크(예: 정치적 코스튬 네트워크와 학술 협업 네트워크)와 합성 SBM 데이터를 사용했다. 결과는 두 방법 모두 무작위 선택이나 고도 중심성 기반 선택보다 빠르게 정확도를 향상시켰으며, 특히 초기 몇 단계에서 특정 ‘핵심 정점’이 반복적으로 선택되는 현상이 관찰되었다. 이는 해당 정점이 전체 블록 구조를 가장 잘 드러내는 정보원임을 시사한다. 또한, 모델이 비동질적(디스어소시어티브) 구조를 포함하더라도 방법론이 견고함을 확인했다.
이 논문의 주요 기여는 (1) SBM 기반 네트워크에서 숨겨진 속성을 효율적으로 학습하기 위한 두 가지 능동 질의 기준을 제시한 점, (2) MI와 AA가 실제 네트워크에 적용될 때 단순 중심성 히어스틱을 크게 능가한다는 실증적 증거, (3) 초기 질의 단계에서 특정 정점이 반복적으로 선택되는 현상을 통해 네트워크 내 ‘정보 중심 정점’ 개념을 정량화했다는 점이다. 향후 연구는 더 복잡한 그래프 생성 모델(예: degree‑corrected SBM)이나, 질의 비용이 정점마다 다를 때의 최적 정책 설계 등으로 확장될 수 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기