디지털 텍스트 스테가노그래피 최신 동향과 구현 기법
초록
본 논문은 ASCII 텍스트를 은폐 매체로 활용한 디지털 스테가노그래피 기술을 전반적으로 조사하고, 용어 정의, 모델링, 분류 체계, 응용 분야 및 주요 은닉 방법(약어, 맞춤법 변형, 동의어 교체 등)을 정리한다. 또한 순수형, 비밀키형, 공개키형 스테가노시스템과 은닉·탐지 모델을 제시하며, 현재 연구의 한계와 향후 과제를 논한다.
상세 분석
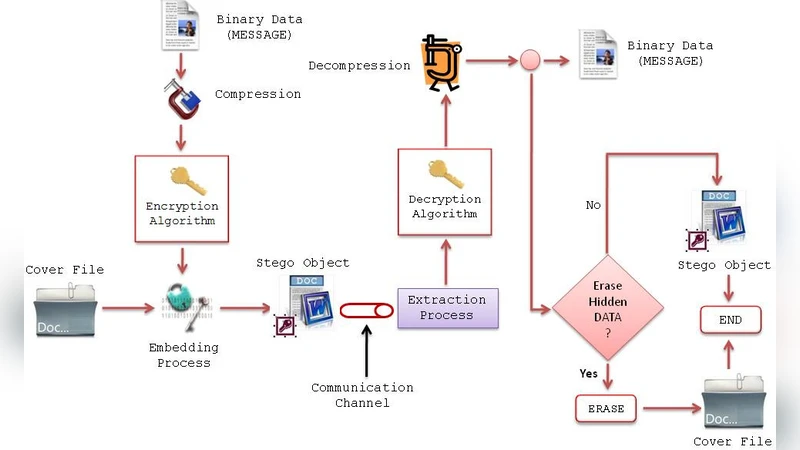
이 논문은 디지털 스테가노그래피를 정보 은폐와 암호화의 결합으로 바라보며, 특히 ASCII 기반 텍스트 문서를 은폐 매체로 삼는 방법에 초점을 맞춘다. 먼저 “커버 텍스트”와 “스테고 텍스트”라는 용어를 정의하고, 은닉 과정은 압축‑암호‑스테가키 적용 후 커버에 삽입하는 3단계 함수 η 로 모델링한다. 복호화는 역함수 Ȩ 로 표현되며, 압축·복호화·복원 과정을 명시한다. 분류 측면에서는 언어학적 기법(구문·의미 활용)과 기술적 기법(대체, 변환, 스펙트럼, 통계, 왜곡, 커버 생성)으로 나누고, 각각의 장·단점을 제시한다. 특히 텍스트 스테가노그래피는 데이터 용량이 제한적이지만, 구현 장치가 필요 없고 인간 눈에 거의 인지되지 않는 장점이 있다. 그러나 Kerckhoffs 원칙을 위배하는 경우가 많아 키 관리와 알고리즘 공개 시 보안성이 저하될 위험이 있다. 주요 은닉 방법으로는 약어 치환, 영·미국식 맞춤법 차이 활용, 동의어 교체, 의도적 오탈자 삽입 등이 소개되며, 각각은 비트 매핑 표를 기반으로 0·1을 결정한다. 이러한 기법은 구현이 간단하지만, 사전 기반 매핑이 고정돼 공격자가 사전 분석을 통해 쉽게 복원할 수 있다는 보안상의 한계가 있다. 논문은 또한 스테가노시스템을 순수형, 비밀키형, 공개키형으로 구분하고, 각각의 키 관리 요구사항과 공격 모델을 논의한다. 탐지 모델은 사전 지식이 없는 블라인드 탐지와, 파일 형식·속성 기반 분석을 통한 분석 모델로 나뉜다. 전체적으로 본 논문은 텍스트 스테가노그래피의 이론적 틀과 실용적 구현 예시를 포괄하지만, 최신 머신러닝 기반 탐지 기법이나 대규모 코퍼스 활용 방안에 대한 논의가 부족한 점이 눈에 띈다. 향후 연구는 동적 텍스트 생성, 자연어 생성 모델과의 결합, 그리고 통계적 탐지 회피 전략을 중심으로 진행될 필요가 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기