네트워크 커뮤니티 통계적 의미 평가
초록
본 논문은 무작위 그래프에서 관측되는 커뮤니티가 실제 네트워크에서 의미 있는지 판단하기 위한 통계적 프레임워크를 제시한다. 극값 이론과 순서 통계학을 이용해 임의 그래프에서 단일 커뮤니티가 나타날 확률을 계산하고, 이를 기반으로 커뮤니티의 p‑값을 정의한다. 실험을 통해 실제 네트워크의 여러 커뮤니티에 대한 유의성을 정량적으로 평가한다.
상세 분석
이 연구는 네트워크 과학에서 가장 기본적인 문제 중 하나인 “커뮤니티가 실제로 의미 있는가?”라는 질문에 답하고자 한다. 기존의 커뮤니티 탐지 알고리즘은 내부 연결 밀도가 높은 서브그래프를 찾아내지만, 이러한 구조가 무작위 네트워크에서도 우연히 발생할 가능성을 무시한다. 저자들은 이를 보완하기 위해 두 가지 통계적 도구, 즉 Extreme Value Theory(극값 이론)와 Order Statistics(순서 통계)를 도입한다.
먼저, 무작위 그래프 모델(주로 Erdős–Rényi 혹은 구성 모델)을 기준으로 각 노드가 가질 수 있는 내부 연결 수의 분포를 추정한다. 이때, 특정 크기 s와 내부 연결 수 k를 가진 서브그래프가 나타날 확률을 정확히 계산하기는 어렵지만, 큰 네트워크에서는 극값 분포(예: Gumbel, Weibull 등)를 이용해 근사할 수 있다. 저자들은 “가장 큰 내부 연결 수”에 대한 극값 분포를 구하고, 이를 통해 임의 그래프에서 동일한 크기의 커뮤니티가 k 이상의 내부 연결을 가질 확률을 p‑값으로 정의한다.
다음으로, 순서 통계학을 활용해 여러 후보 커뮤니티 중 가장 유의한 하나를 선택하는 과정에서 발생하는 다중 비교 문제를 정량화한다. 즉, N개의 후보 커뮤니티 중 최소 p‑값을 관측했을 때, 그 최소값이 무작위 그래프에서 기대되는 최소값보다 얼마나 작은지를 평가한다. 이를 통해 “전체 클러스터링 결과가 무작위와 구별되는가”를 판단할 수 있다.
알고리즘 측면에서는 기존 커뮤니티 탐지 방법(예: modularity 최적화, Infomap 등)으로 얻은 커뮤니티 집합에 대해 각각 위의 통계적 검정을 적용한다. 각 커뮤니티에 대해 (s, k) 쌍을 계산하고, 사전 정의된 무작위 모델 파라미터(노드 수, 평균 차수 등)를 사용해 해당 (s, k) 조합의 p‑값을 구한다. p‑값이 사전 설정된 유의 수준(예: 0.05)보다 작으면 해당 커뮤니티를 “통계적으로 유의하다”고 판단한다.
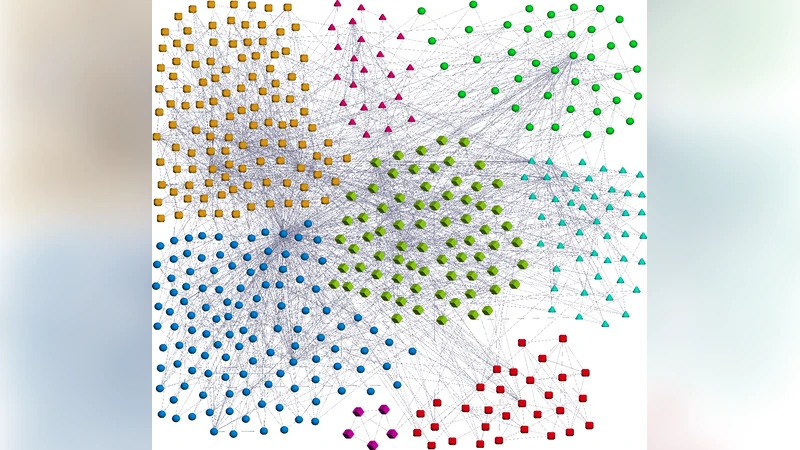
실험에서는 합성 네트워크와 실제 사회·생물·기술 네트워크를 대상으로 방법을 검증한다. 합성 실험에서는 planted partition 모델을 사용해 알려진 커뮤니티를 삽입하고, 제안된 통계 검정이 실제 커뮤니티를 높은 정확도로 식별함을 보인다. 실제 네트워크에서는 정치적 파벌, 단백질 복합체, 인터넷 AS 관계 등 다양한 도메인의 커뮤니티에 대해 p‑값을 계산하고, 기존 연구에서 제시된 의미 있는 커뮤니티와 일치하거나 새로운 의미 있는 구조를 발견한다.
이 논문의 주요 기여는 (1) 커뮤니티의 통계적 유의성을 정량화하는 명확한 확률 모델을 제공, (2) 극값 및 순서 통계 이론을 네트워크 분석에 성공적으로 적용, (3) 기존 탐지 결과에 사후 검증을 수행함으로써 과대 해석을 방지한다는 점이다. 다만, 무작위 모델 선택에 따라 결과가 민감하게 변할 수 있으며, 매우 큰 커뮤니티에 대해서는 극값 근사가 부정확해질 가능성이 있다. 향후 연구에서는 보다 정교한 null model(예: degree‑preserving randomization)과 베이지안 프레임워크를 결합해 검정의 강건성을 높일 여지가 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기