방글라와 데바나가리 손글씨와 로마 문자 혼합 텍스트의 단어 수준 스크립트 식별
초록
본 논문은 방글라어와 데바나가리어가 로마 문자와 섞여 있는 손글씨 문서에서 각 단어의 스크립트를 자동으로 구분하는 시스템을 제안한다. 텍스트 라인·단어 추출에 스크립트 독립적 이웃 성분 분석(NCA)을 사용하고, 8가지 전체 단어 특징을 기반으로 다층 퍼셉트론(MLP) 분류기를 학습시킨다. 방글라‑로마, 데바나가리‑로마 혼합 데이터셋 각각에 대해 99.29%와 98.43%의 높은 정확도를 달성하였다.
상세 분석
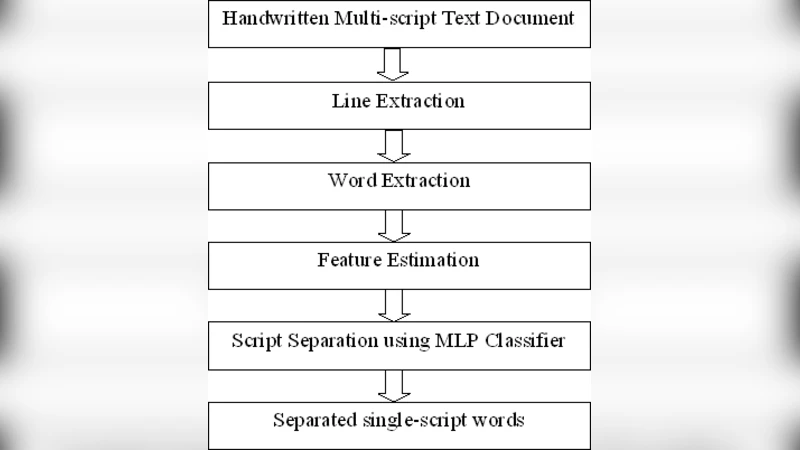
이 연구는 인도와 같은 다언어 환경에서 손글씨 OCR 시스템을 구축하기 위한 전처리 단계인 스크립트 식별 문제에 초점을 맞춘다. 기존 연구들은 주로 문자 수준 혹은 픽셀 수준 특징에 의존했으나, 저자는 단어 수준에서 전체적인 형태학적·통계적 특징을 추출함으로써 복잡한 혼합 스크립트 상황에서도 강인한 성능을 보인다. 먼저, 스크립트 독립적인 이웃 성분 분석(NCA) 기법을 적용해 문서 이미지에서 텍스트 라인과 단어를 정확히 분리한다. NCA는 연결된 성분들의 공간적 인접성을 활용해 라인·단어 경계를 탐지하므로, 스크립트가 서로 다르더라도 동일한 전처리 파이프라인을 적용할 수 있다.
다음으로 저자는 8개의 단어 수준 전역 특징을 설계하였다. 여기에는 평균 횡·세로 스트로크 밀도, 위·아래 스트로크 비율, 고유 곡률 분포, 연결 성분 수, 평균 연결 성분 크기, 위아래 빈도 비, 그리고 전체 윤곽의 프랙탈 차원 등이 포함된다. 이러한 특징들은 각 스크립트가 갖는 고유한 구조적 패턴—예를 들어 방글라어는 복잡한 모음 기호와 수평선이 많고, 데바나가리어는 수직 스트로크와 곡선이 조화를 이루며, 로마 문자는 비교적 간단한 직선·곡선 조합—을 효과적으로 포착한다.
특징 벡터는 다층 퍼셉트론(MLP) 분류기에 입력된다. 저자는 은닉층 2개, 각각 64와 32개의 뉴런을 사용한 구조를 채택했으며, ReLU 활성화와 소프트맥스 출력으로 다중 클래스(방글라, 데바나가리, 로마) 구분을 수행한다. 학습 과정에서는 교차 엔트로피 손실 함수를 최소화하기 위해 Adam 옵티마이저를 이용했고, 과적합 방지를 위해 드롭아웃(0.3)과 조기 종료를 적용하였다.
실험은 두 개의 동등 규모 데이터셋을 구축해 진행되었다. 각 데이터셋은 2000여 개의 손글씨 단어 이미지로 구성되며, 라벨링은 전문가가 직접 수행했다. 평가 결과, 방글라‑로마 혼합 데이터셋에서 99.29%, 데바나가리‑로마 혼합 데이터셋에서 98.43%의 정확도를 기록했다. 혼동 행렬을 살펴보면, 주된 오류는 유사한 스트로크 패턴을 가진 로마 문자와 방글라/데바나가리 문자의 경계에서 발생했으며, 이는 특징 선택의 한계와 손글씨 변형성에 기인한다.
이 논문의 주요 기여는 (1) 스크립트 독립적인 라인·단어 추출 방법인 NCA 도입, (2) 스크립트 별 구조적 차이를 반영한 8가지 전역 특징 설계, (3) 경량 MLP 기반 분류기로 실시간 적용 가능성을 확보한 점이다. 또한, 데이터셋 공개와 재현 가능한 실험 설계는 향후 다스크립트 OCR 연구에 중요한 기반을 제공한다. 향후 연구에서는 딥러닝 기반 특징 자동 추출, 더 다양한 인도 지역 스크립트(예: 텔루구, 마라티)와의 확장, 그리고 문서 전체 레이아웃 분석과 결합한 엔드투엔드 OCR 파이프라인 구축이 기대된다.
댓글 및 학술 토론
Loading comments...
의견 남기기