알파벳식 이분 그래프를 통한 생명·언어 조합 시스템 모델링
초록
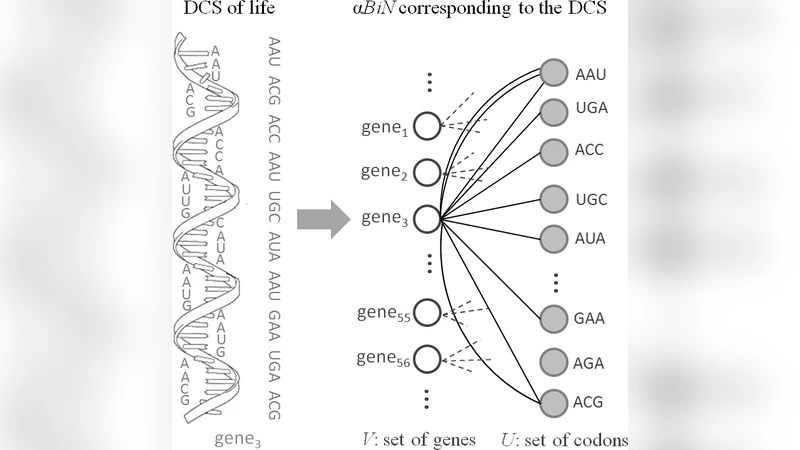
본 논문은 염기·코돈과 문자·음소와 같은 유한 기본 단위들의 조합으로 이루어진 생명·언어 시스템을 알파벳식 이분 그래프(α‑BiN)로 모델링한다. 고정된 기본 단위 파티션과 무한히 성장하는 조합 파티션을 가정하고, 순차 및 병렬 연결 규칙에 따른 성장 방정식을 도출한다. 분석 결과, 시간에 따라 α‑BiN의 차수 분포는 베타 분포 계열로 수렴하며, 무작위성 파라미터 γ에 따라 정규, 왜곡 정규, 지수, U‑형 네 가지 형태로 변한다. 실제 코돈‑유전자 네트워크와 음소‑언어 네트워크에 적용해 이론과 실험 결과를 비교함으로써 성장 메커니즘을 추정하는 방법을 제시한다.
상세 분석
α‑BiN은 두 파티션 U(기본 단위)와 V(조합)으로 구성된 이분 그래프이며, U는 고정된 크기 N을, V는 시간에 따라 무한히 확장된다. 각 시간 단계에서 V에 새로운 노드 v_i가 추가되고, v_i는 μ개의 엣지를 U의 노드에 연결한다. 연결 규칙은 선호적 연결과 무작위성을 조절하는 파라미터 γ(또는 초기 매력 α=1/γ)를 포함하는 커널 e_A(k_i)= (γk_i+1)/(γμt+N) 로 정의된다. μ=1인 경우는 순차적 연결이며, μ>1은 병렬 연결이다. 병렬 연결은 다시 교체 가능(with replacement)과 교체 불가(without replacement)로 나뉘며, 전자는 다중 엣지를 허용하고 후자는 단일 엣지만 허용한다.
연립 방정식 p_{k,t+1}= (1−A_p(k,t))p_{k,t}+A_p(k−1,t)p_{k−1,t} 를 통해 U 파티션의 차수 분포 p_{k,t} 를 근사적으로 풀었다. 여기서 A_p(k,t)= (γk+1)μ/(γμt+N) 이다. 해는 베타 함수 형태의 복합 곱으로 표현되며, t→∞ 일 때 p_{k,t}는 베타 분포 계열에 수렴한다. γ의 크기에 따라 네 가지 전형적인 형태가 나타난다: (a) γ=0 → 이항(또는 포아송) 분포, (b) 0<γ<1 → 이동하는 피크를 가진 왜곡 정규형, (c) 1≤γ≤(N/μ)−1 → 단조 감소형(지수형에 가까움), (d) γ>(N/μ)−1 → U‑형(양끝에 높은 확률)이다.
이론적 결과를 실제 데이터에 적용하기 위해 코돈‑유전자 네트워크와 음소‑언어 네트워크를 구축하였다. 코돈‑유전자 네트워크에서는 복잡도가 높은 생물일수록 γ가 크게 추정되어 무작위성이 강조됨을 확인했다. 반면 음소‑언어 네트워크에서는 실제 차수 분포가 이론적 U‑형과 일치하지 않아, 단순 선호적 연결 모델만으로는 언어 내 음소 공존 구조를 완전히 설명하지 못함을 지적한다. 이는 실제 성장 메커니즘이 더 복합적이며, 예를 들어 음소 간 상호작용, 문화적 전파, 혹은 진화적 제약 등이 추가 모델링되어야 함을 시사한다.
마지막으로, α‑BiN의 일방향 투영(One‑mode projection)인 U‑U 네트워크의 차수 분포를 분석했지만, 이론과 실험 사이에 차이가 존재한다. 이는 병렬 연결 시 다중 엣지와 가중치가 투영 과정에서 복합적인 효과를 일으키기 때문이다. 따라서 향후 연구에서는 가중치 기반 투영, 동적 파라미터 변동, 그리고 비정렬 조합(예: 순서가 중요한 경우) 등을 고려한 확장 모델이 필요하다.
댓글 및 학술 토론
Loading comments...
의견 남기기