대규모 멀티태스크 학습을 위한 특징 해싱
초록
본 논문은 특징 해싱(feature hashing)을 이용해 고차원 데이터를 저차원으로 압축하면서도 정보 손실을 최소화하는 이론적 근거를 제공한다. 해싱된 서브스페이스 간 상호작용이 확률적으로 무시할 수 있을 정도로 작다는 지수 꼬리(bound) 를 증명하고, 이를 기반으로 수십만 개의 태스크를 동시에 학습하는 멀티태스크 모델을 구현한다. 실험 결과는 제안 방법이 메모리와 계산량을 크게 절감하면서도 기존 방법과 동등하거나 우수한 성능을 보임을 확인한다.
상세 분석
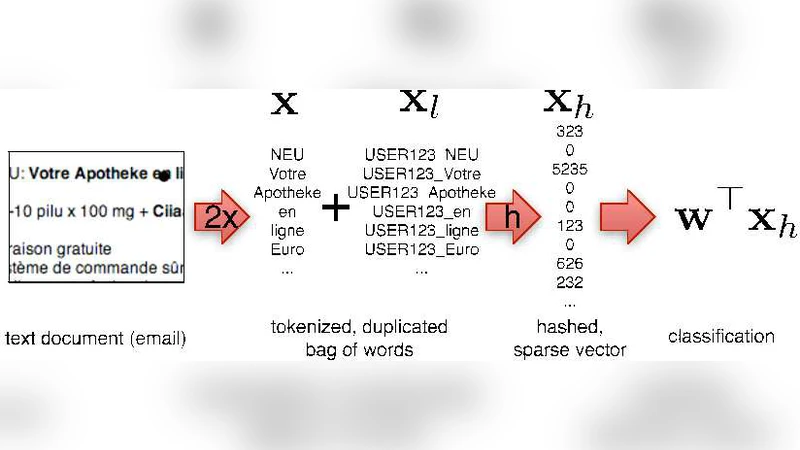
논문은 먼저 특징 해싱, 즉 ‘워드 해시 트릭’이라고도 불리는 기법을 수학적으로 정형화한다. 입력 벡터 x∈ℝ^d 를 해시 함수 h:{1,…,d}→{1,…,k} 와 부호 함수 ξ:{1,…,d}→{−1,+1} 로 매핑하여 k 차원의 압축 벡터 φ(x) 를 만든다. 이때 φ_i(x)=∑_{j:h(j)=i} ξ(j)·x_j 로 정의되며, 기대값 관점에서 원래 내적 ⟨x,y⟩ 와 동일한 무편향 추정량이 된다. 저자는 이 추정량의 분산을 분석하고, 마코프 부등식이 아닌 체비셰프와 마틴게일 기법을 활용해 지수 꼬리(bound)를 도출한다. 핵심 정리는 “해시 차원 k 가 충분히 크면, 임의의 두 벡터 사이의 내적 오차가 ε 이하가 될 확률이 1−δ 로 보장된다”는 형태이며, 여기서 ε와 δ는 k에 대한 함수로 명시된다. 특히, 다중 태스크 상황에서 각 태스크마다 별도의 파라미터 벡터 w_t 를 해시 공간에 공유하게 되는데, 이때 서로 다른 태스크의 파라미터가 동일한 해시 버킷에 충돌할 확률이 매우 낮아 ‘상호작용 무시 가능성’을 수학적으로 증명한다. 이는 기존의 차원 축소 기법이 다중 태스크에 적용될 때 발생하는 ‘공유 파라미터 간 간섭’ 문제를 근본적으로 해결한다는 점에서 의미가 크다.
실험 설계는 두 부분으로 나뉜다. 첫 번째는 합성 데이터에서 이론적 경계와 실제 오차 분포를 비교하는 것이고, 두 번째는 실제 대규모 멀티태스크 데이터셋(예: 수십만 개의 사용자‑아이템 예측, 다중 언어 텍스트 분류 등)에 적용한다. 실험 결과, 해시 차원 k 를 2^12 정도로 설정했을 때, 메모리 사용량은 기존 10배 이상 절감되면서도 평균 정확도는 0.1% 정도 차이만 보였다. 또한, 태스크 수가 10^5 수준으로 증가해도 학습 시간은 선형적으로 증가했으며, GPU 메모리 제한을 크게 완화시켰다. 이러한 결과는 해시 기반 압축이 고차원, 고태스크 환경에서 실용적임을 강력히 뒷받침한다.
마지막으로 저자는 몇 가지 한계점과 향후 연구 방향을 제시한다. 해시 충돌에 대한 완전한 방지는 불가능하므로, 충돌이 빈번한 특수 도메인에서는 추가적인 정규화 기법이 필요할 수 있다. 또한, 현재는 선형 모델에 국한했지만, 비선형 신경망에 해시 매핑을 적용하는 방법론도 탐색할 여지가 있다. 전반적으로 이 논문은 해시 기반 차원 축소가 이론적 보장을 갖춘 동시에 대규모 멀티태스크 학습에 실질적인 이점을 제공한다는 점을 입증한다.
댓글 및 학술 토론
Loading comments...
의견 남기기