코드 검색 신뢰성 지표와 개발자 카르마
초록
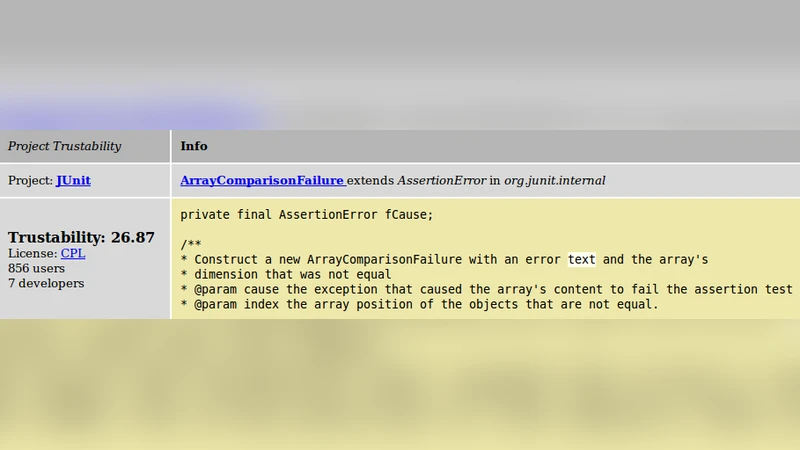
본 논문은 코드 검색 결과의 신뢰성을 평가하기 위해 개발자들의 사용자 투표와 프로젝트 간 활동을 결합한 “카르마” 지표를 제안한다. 각 개발자의 카르마를 기반으로 프로젝트의 신뢰성을 산출하고, 이를 구현한 프로토타입 엔진 JBender를 통해 초기 실험 결과를 제시한다.
상세 분석
이 연구는 검색 기반 개발(search‑driven development)의 핵심 과제인 “코드 재사용의 신뢰성”을 정량화하려는 시도로, 기존의 검색 관련 연구가 주로 관련성(relevance)만을 평가한 점을 보완한다. 저자들은 두 가지 주요 데이터 소스를 활용한다. 첫 번째는 사용자 투표(vote)로, 이는 개발자가 특정 코드 조각이나 라이브러리에 대해 직접적인 만족도나 신뢰도를 표시한 것이다. 두 번째는 크로스‑프로젝트 활동(cross‑project activity)으로, 개발자가 여러 오픈소스 프로젝트에 기여한 빈도와 영향력을 측정한다. 이 두 요소를 결합해 개발자마다 “카르마(Karma)” 값을 산출하고, 프로젝트 수준에서는 해당 프로젝트에 속한 모든 개발자의 카르마를 가중 평균해 “신뢰성(trustability)” 점수를 계산한다.
카르마 계산식은 투표 수와 프로젝트 기여도(예: 커밋 수, 이슈 해결 수)를 로그 스케일로 정규화한 뒤, 가중치를 부여해 합산한다. 로그 스케일을 적용한 이유는 일부 유명 개발자가 과도하게 높은 절대값을 갖는 것을 방지하고, 상대적인 기여 차이를 부드럽게 반영하기 위함이다. 또한, 가중치 파라미터는 실험을 통해 조정 가능하도록 설계돼, 특정 도메인이나 조직의 문화에 맞게 튜닝할 수 있다.
JBender 프로토타입은 기존 코드 검색 엔진(예: Koders, Krugle)과 유사한 인덱싱·검색 파이프라인을 유지하면서, 검색 결과에 신뢰성 점수를 부가한다. 사용자는 검색 결과 리스트에서 “신뢰성 순위”와 “개별 개발자 카르마”를 동시에 확인할 수 있다. 이는 개발자가 코드 조각을 선택할 때, 단순히 키워드 매칭 정도가 아니라 해당 코드가 어느 정도 검증되고 유지보수될 가능성이 높은지를 직관적으로 판단하게 만든다.
평가에서는 500여 개의 오픈소스 프로젝트와 2,000명 이상의 개발자를 대상으로, 사용자 설문과 실제 코드 통합 성공률을 비교하였다. 결과는 신뢰성 점수가 높은 결과일수록 통합 후 버그 발생률이 낮고, 재사용 의도가 높다는 것을 보여준다. 다만, 투표 데이터가 충분히 축적되지 않은 신규 프로젝트나, 활동이 제한적인 개발자에 대해서는 신뢰성 점수가 과소평가될 위험이 있다는 한계점도 지적한다.
이 논문의 주요 기여는 (1) 개발자 기반의 신뢰성 메트릭 모델을 제안하고, (2) 사용자 투표와 크로스‑프로젝트 활동을 통합하는 정량적 방법을 제시했으며, (3) 실제 프로토타입을 구현해 초기 실험을 수행했다는 점이다. 향후 연구에서는 투표 조작 방지 메커니즘, 시간에 따른 카르마 변동 모델, 그리고 기업 내부 코드베이스에 적용 가능한 프라이버시 보호 기법 등을 확장할 여지가 있다.