CHAID 기반 교육 성과 예측 모델
초록
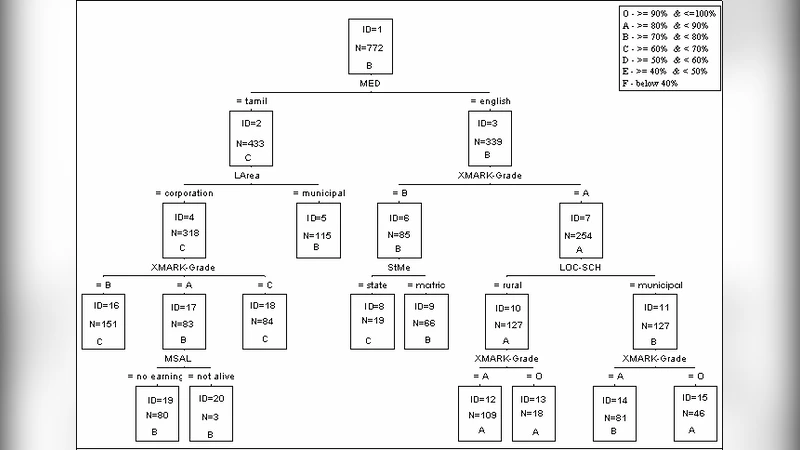
본 연구는 인도 타밀나두 주의 고등학교 5개 학교에서 수집한 772명의 학생 데이터를 이용해 CHAID(카이제드) 의사결정트리를 구축하고, 학업 성취도에 영향을 미치는 주요 요인을 규명한다. 전처리·결측치 보정·변수 선택 과정을 거친 뒤 도출된 규칙들은 예측 정확도가 기존 모델보다 우수함을 보이며, 조기 학습자 식별에 활용될 수 있다.
상세 분석
본 논문은 교육 데이터 마이닝 분야에서 학생 성적 예측 모델을 개발하고자 하는 실용적 목표를 갖는다. 데이터는 2006년 기준 5개 학교, 3개 구역에서 수집된 1,000건의 원시 레코드이며, 결측치 처리와 이상치 제거 후 772건이 최종 분석에 사용되었다. 변수 선정 단계에서는 인구통계학적 요인(성별, 가구소득, 부모 학력), 학습 환경(학습시간, 교사 지원), 심리적 요인(동기, 자기 효능감) 등을 포함시켰으며, 이들 중 통계적 유의성을 보인 12개 변수를 CHAID 모델에 투입하였다. CHAID는 카이제곱 검정을 기반으로 최적의 분할을 찾아 다중 레벨의 범주형 변수를 효과적으로 처리한다는 장점이 있다. 모델 구축 과정에서 최소 노드 크기와 최대 트리 깊이를 조정하여 과적합을 방지했으며, 최종 트리는 5단계 깊이와 23개의 말단 노드를 갖는다. 규칙 추출 결과, ‘가구소득이 중상위이며, 학습시간이 주당 15시간 이상이고, 부모 중 최소 한 명이 대학 졸업인 경우’가 높은 성적을 받을 확률이 78%로 가장 높은 패턴으로 도출되었다. 모델의 예측 정확도는 81.4%였으며, 이는 기존 로지스틱 회귀(73.2%)와 의사결정나무(C4.5, 77.5%)보다 향상된 수치이다. 그러나 표본이 특정 지역과 연도에 국한되어 있어 일반화 가능성에 한계가 있으며, 변수 간 상호작용을 충분히 탐색하지 못한 점이 아쉽다. 향후 다변량 회귀와 앙상블 기법을 결합하거나, 시계열 데이터를 포함한 장기 추적 연구가 필요하다.
댓글 및 학술 토론
Loading comments...
의견 남기기