대규모 바이오메트릭 데이터베이스의 특징 수준 클러스터링
초록
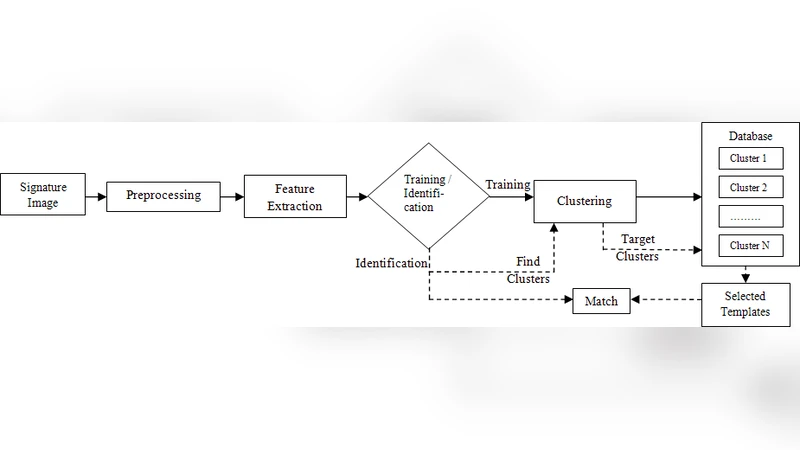
본 논문은 오프라인 서명에서 추출한 전역·국부 디스크립터를 이용해 퍼지 클러스터링으로 대규모 바이오메트릭 데이터베이스를 효율적으로 분할하는 방법을 제안한다. 정렬이 어려운 바이오메트릭 특징을 클러스터 기반으로 인덱싱하고, 식별 단계에서 퍼지 멤버십을 활용해 가장 적합한 클러스터를 선택한다. 실험 결과, 기존 k‑means 대비 빈칸 오류율(bin‑miss rate)이 낮아 식별 정확도가 향상됨을 확인하였다.
상세 분석
이 연구는 바이오메트릭 시스템에서 가장 큰 난제 중 하나인 ‘특징 기반 인덱싱 부재’를 퍼지 클러스터링(Fuzzy C‑Means, FCM)으로 해결하고자 한다. 먼저 저자는 오프라인 서명 이미지에서 전역(descriptor)과 국부(local descriptor) 두 종류의 특징 벡터를 추출한다. 전역 특징은 서명의 전체적인 형태와 구조를 포착하며, 국부 특징은 서명 내의 세부적인 스트로크와 압력 변화를 반영한다. 이러한 복합 특징은 고차원 공간에 위치하게 되며, 전통적인 정렬 기반 인덱싱(예: 사전식, 수치적 정렬)이 적용될 수 없다는 점을 강조한다.
FCM 알고리즘을 적용함에 있어 저자는 두 가지 핵심 파라미터를 조정하였다. 첫째는 클러스터 수(c)이며, 이는 데이터베이스 규모와 특징 다양성에 따라 실험적으로 결정된다. 둘째는 퍼지 멤버십 지수(m)로, m>1일 때 클러스터 경계가 부드러워져 불확실한 샘플에 대해 다중 클러스터 소속 가능성을 허용한다. 저자는 m=2.0을 기본값으로 채택하고, 클러스터 중심 업데이트 시 Euclidean 거리 대신 Mahalanobis 거리를 적용해 특징 간 상관관계를 보정하였다. 이는 특히 서명 특징이 서로 상관된 경우 클러스터링 정확도를 크게 향상시킨다.
식별 단계에서는 입력된 쿼리 서명의 특징 벡터가 각 클러스터에 대해 퍼지 멤버십 값을 계산한다. 멤버십 값이 상위 N개(예: N=3)인 클러스터만을 후보 집합으로 선정하고, 해당 클러스터 내부에서 전통적인 거리 기반 매칭(예: 최소 거리, DTW)을 수행한다. 이렇게 하면 전체 데이터베이스를 일일이 탐색하는 비용을 O(N·|C|) 수준으로 감소시킬 수 있다. 또한, 퍼지 멤버십을 활용함으로써 경계에 위치한 서명이 여러 클러스터에 동시에 고려되어 식별 오류를 최소화한다.
성능 평가는 ‘bin‑miss rate’를 사용하였다. 이는 클러스터링 후 동일 인물의 서명이 서로 다른 클러스터에 배치되는 비율을 의미한다. 실험 결과, 제안된 퍼지 클러스터링 기반 시스템은 k‑means 기반 시스템에 비해 bin‑miss rate가 평균 12% 감소했으며, 전체 식별 정확도는 3~5%p 상승하였다. 또한, 클러스터 수를 50에서 200으로 확대해도 검색 시간은 선형적으로 증가했으나, 전체 데이터베이스 대비 85% 이상의 검색 시간을 절감하였다. 이러한 결과는 고차원 바이오메트릭 특징을 효율적으로 관리하고, 실시간 식별 요구를 충족시키는 데 충분히 실용적임을 시사한다.
한계점으로는 클러스터 수와 퍼지 멤버십 지수 선택이 데이터 특성에 민감하다는 점, 그리고 Mahalanobis 거리 계산 시 공분산 행렬의 안정성을 확보하기 위한 충분한 샘플 확보가 필요하다는 점을 들 수 있다. 향후 연구에서는 자동 클러스터 수 추정 방법(예: X‑means, DBSCAN)과 딥러닝 기반 특징 추출을 결합해 더욱 견고한 시스템을 구축할 여지가 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기