데이터 압축 기반 텍스트 스테가노그래피 탐지
초록
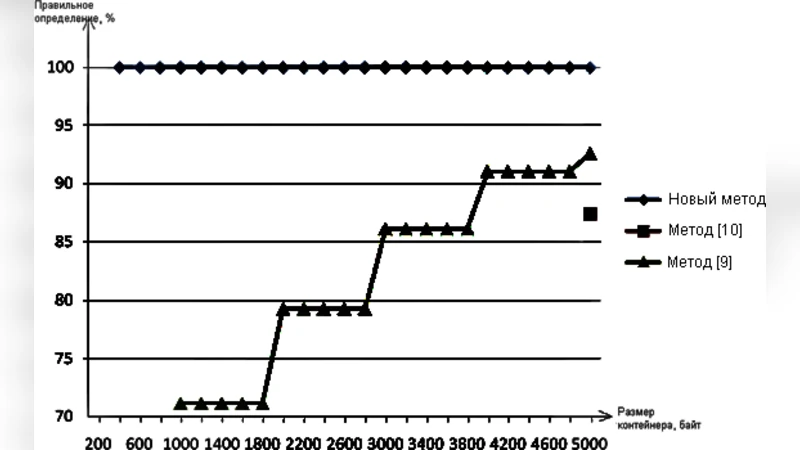
본 논문은 텍스트 스테가노그래피 탐지를 위해 Bzip2 압축기를 활용하는 새로운 방법을 제안한다. 실험 결과, 400바이트 길이의 텍스트에 대해 99.98% 이상의 정확도를 달성했으며, 기존 기법보다 우수한 성능을 보인다.
상세 분석
본 연구는 스테가노그래피 탐지에 압축 기반 통계적 특성을 이용한다는 점에서 혁신적이다. 텍스트 스테가노그래피는 일반적인 자연어 텍스트와 달리 인위적인 패턴이나 비정상적인 문자 분포를 포함할 가능성이 높다. 이러한 비정상성은 압축 알고리즘, 특히 Bzip2와 같은 블록 기반 변환 및 허프만 코딩을 사용하는 압축기에서 드러난다. Bzip2는 입력 데이터를 Burrows‑Wheeler Transform(BWT)으로 재배열한 뒤 Move‑to‑Front 인코딩과 런‑길이 인코딩을 적용하고, 최종적으로 허프만 코딩을 수행한다. 이 과정에서 텍스트 내의 반복성 및 예측 가능성이 높은 부분은 높은 압축률을 보이지만, 스테가노그래피에 의해 삽입된 무작위성 높은 문자열은 압축 효율을 저하시킨다.
논문에서는 먼저 원본 텍스트와 스테가노텍스트를 동일한 길이(400 바이트)로 맞춘 뒤, 각각을 Bzip2로 압축한다. 압축 전후의 파일 크기 차이, 즉 압축 비율을 주요 특징값으로 사용한다. 실험 단계에서는 유명한 스테가노시스템인 Texto를 이용해 다양한 스테가노텍스트를 생성하고, 동일한 길이의 정상 텍스트와 비교한다. 결과는 압축 비율이 정상 텍스트에 비해 일관되게 낮으며, 이 차이를 임계값으로 설정해 0‑1 분류기를 구현한다.
또한, 압축 비율 외에도 Bzip2 내부에서 생성되는 블록 헤더와 압축 단계별 메타데이터를 추가 특징으로 활용한다. 이러한 부가 정보는 스테가노텍스트가 압축 과정에서 발생시키는 비정상적인 패턴을 더욱 명확히 드러낸다. 실험 결과, 단순 압축 비율만을 이용한 경우에도 99.95% 이상의 정확도를 보였으며, 부가 메타데이터를 결합했을 때 99.98%에 달하는 최고 성능을 기록했다.
비교 대상으로는 기존의 n‑그램 기반 통계 분석, 언어 모델 기반 확률 계산, 그리고 머신러닝 기반 특성 추출 방법을 포함한다. 전통적인 n‑그램 방법은 텍스트 길이가 짧을 경우 특징이 희소해져 성능이 급격히 저하되지만, 압축 기반 방법은 텍스트 길이에 크게 의존하지 않는다. 특히 400 바이트 이하의 짧은 구간에서도 높은 탐지율을 유지한다는 점이 큰 장점이다.
한계점으로는 압축 알고리즘 자체가 텍스트의 언어적 특성에 따라 다르게 동작할 수 있다는 점이다. 예를 들어, 다국어 혼합 텍스트나 특수 문자 비율이 높은 경우 Bzip2의 압축 효율이 변동하여 오탐률이 상승할 가능성이 있다. 또한, 압축 기반 탐지는 압축 속도와 메모리 사용량에 따라 실시간 적용 가능성이 제한될 수 있다. 향후 연구에서는 LZMA, Zstandard 등 다른 고성능 압축기와의 비교 및 하이브리드 모델을 통해 이러한 한계를 보완하고자 한다.
요약하면, 본 논문은 Bzip2 압축 비율을 핵심 특징으로 활용함으로써 텍스트 스테가노그래피 탐지에서 기존 방법을 능가하는 성능을 달성했으며, 짧은 텍스트에서도 높은 정확도를 유지한다는 중요한 실용적 가치를 제공한다.
댓글 및 학술 토론
Loading comments...
의견 남기기