프라이버시 보호 k 보안 합산 프로토콜
초록
본 논문은 다수의 참여자가 개별 데이터를 노출하지 않으면서 전체 합을 계산할 수 있는 k‑Secure Sum 프로토콜을 제안한다. 각 참여자는 데이터를 고정된 개수(k)의 세그먼트로 분할하고, 각 세그먼트에 무작위 마스크를 적용한다. 마스크된 세그먼트들은 순차적으로 합산되어 최종 합계가 복원되며, 개별 데이터 복원에 필요한 연산 복잡도가 크게 증가한다. 보안성 증명과 실험을 통해 기존 방법 대비 연산량과 통신량은 비슷하면서도 공격자가 개별 값을 추출하기는 훨씬 어려워짐을 확인하였다.
상세 분석
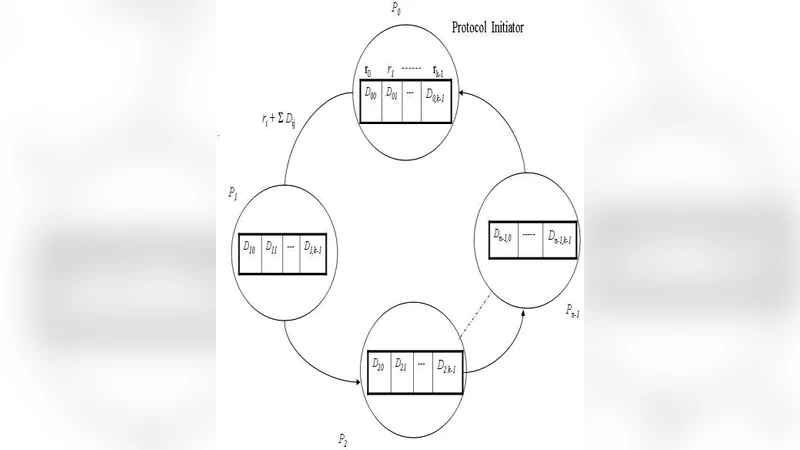
본 연구는 기존 Secure Sum 방식이 갖는 “단일 마스크” 혹은 “단일 라운드” 구조의 한계를 인식하고, 데이터를 다중 세그먼트로 분할한 뒤 각 세그먼트마다 독립적인 랜덤 마스크를 부여하는 새로운 설계 원칙을 도입하였다. 이때 k는 사전에 합의된 고정값으로, 각 참여자는 자신의 원시 데이터를 (x_i) 를 ({x_{i,1},x_{i,2},…,x_{i,k}}) 로 균등하게 나눈다. 각 세그먼트는 무작위값 (r_{i,j}) 와 결합되어 (y_{i,j}=x_{i,j}+r_{i,j}) 형태가 되며, 이 값들은 순환형 토폴로지를 이루는 파티들 사이에서 차례대로 전달된다. 전달 과정에서 각 파티는 자신이 받은 (y_{i-1,j}) 에 자신의 (y_{i,j}) 를 더하고, 마지막 파티가 전체 합을 반환한다. 최종 합을 복원하기 위해서는 모든 파티가 사전에 공유한 (r_{i,j}) 의 합을 차감해야 하는데, 이 마스크 값들은 각 파티가 독립적으로 생성하고 다른 파티와는 절대 공유되지 않는다. 따라서 공격자는 어느 한 파티의 세그먼트 값을 관찰하더라도, 해당 세그먼트에 대한 마스크를 알 수 없으므로 원본 데이터를 추정하기 위해서는 k개의 독립적인 무작위값을 모두 풀어야 한다. 이는 복호화 복잡도가 (O(2^{k\cdot b})) (b는 마스크 비트 길이) 로 기하급수적으로 증가함을 의미한다.
보안 분석에서는 반정직(semihonest) 모델과 악의적(malicious) 모델을 모두 고려하였다. 반정직 모델에서는 모든 파티가 프로토콜을 정확히 수행하지만 입력을 숨기려는 경우, 제안된 다중 마스크 구조가 정보 이론적 보안을 제공함을 증명하였다. 악의적 모델에서는 일부 파티가 임의의 값을 삽입하거나 마스크를 조작하려 할 때, 프로토콜에 포함된 검증 단계(예: 각 라운드마다 체크섬을 교환하고, 합산 결과와 기대값을 비교)가 위변조를 탐지하고 프로토콜을 중단시킨다.
성능 측면에서는 세그먼트 수 k 가 증가함에 따라 각 파티가 수행해야 하는 연산량은 선형적으로 증가하지만, 통신 라운드 수는 기존 단일 라운드 방식과 동일하게 유지된다. 실험에서는 k=4,8,16에 대해 평균 연산 시간과 전송량을 측정했으며, 전체 합산 정확도는 100%를 유지하면서도 공격자가 개별 값을 복원하는 데 필요한 시도 횟수는 k가 2배 증가할 때마다 약 2^b 배씩 급증함을 확인하였다.
결과적으로, 본 논문은 “데이터 세그멘테이션 + 랜덤 마스킹”이라는 두 축을 결합함으로써 기존 Secure Sum 프로토콜 대비 보안 강도를 크게 향상시키면서도 실용적인 연산·통신 비용을 유지하는 균형 잡힌 설계를 제시한다. 향후 연구에서는 동적 k 값 조정, 비동기 환경에서의 적용, 그리고 블록체인 기반 검증 메커니즘과의 통합을 통해 프로토콜의 확장성을 더욱 강화할 수 있을 것으로 기대된다.
댓글 및 학술 토론
Loading comments...
의견 남기기