자동화된 단어 안정성 및 언어 계통학
초록
본 논문은 정규화된 레벤슈타인 거리를 이용해 동일 의미의 단어들을 비교하고, 전체 단어 목록에 대한 평균값으로 언어 간 거리를 자동 측정하는 방법을 제안한다. 또한 의미별 단어 안정성을 정량화하여 어휘 변화 속도가 의미와 사용 빈도와 어떻게 연관되는지를 탐구한다.
상세 분석
이 연구는 전통적인 글로토크로놀로지에서 사용되는 공유 인도어 비율 대신, 문자열 편집 거리인 레벤슈타인 거리를 정규화하여 단어 수준에서 직접적인 거리 측정을 수행한다는 점에서 혁신적이다. 정규화는 두 단어 길이의 최댓값으로 나누어 0과 1 사이의 값으로 변환함으로써, 길이가 다른 단어들 간의 비교에서도 편향을 최소화한다. 논문은 먼저 200여 개 언어에 대해 200개의 기본 의미(스와데시 리스트와 유사)를 수집하고, 각 언어 쌍마다 동일 의미에 대한 정규화 레벤슈타인 거리 평균을 계산한다. 이 평균값을 언어 간 거리로 정의하고, 다차원 척도법(MDS)과 계통수 재구성 알고리즘(UPGMA)을 적용해 언어 계통도를 시각화한다. 결과는 기존 인도어 기반 거리와 높은 상관관계를 보이며, 특히 데이터가 부족하거나 인도어 판별이 어려운 경우에도 안정적인 계통 구조를 제공한다는 점에서 실용성을 입증한다.
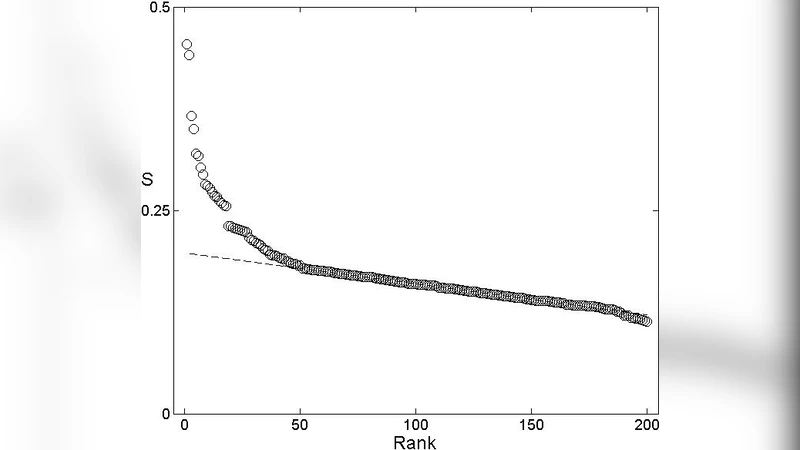
단어 안정성 분석에서는 각 의미별로 모든 언어 쌍에 대한 정규화 레벤슈타인 거리 평균을 구하고, 이를 ‘불안정도’ 지표로 활용한다. 불안정도가 낮은 의미는 전반적으로 형태가 보존되는 경향이 강하고, 높은 의미는 빠른 어휘 교체 혹은 차용이 일어나는 것으로 해석한다. 논문은 이러한 불안정도와 해당 의미의 사용 빈도(코퍼스 기반 빈도 데이터) 사이에 음의 상관관계가 있음을 통계적으로 확인한다. 즉, 자주 사용되는 단어일수록 형태적 보존력이 높아 안정성이 높다는 가설을 정량적으로 뒷받침한다.
또한, 불안정도 지표를 활용해 의미 선택을 최적화함으로써, 전통적인 스와데시 리스트보다 더 효율적인 ‘핵심 의미 집합’을 제시한다. 이 집합은 언어 간 거리 계산 시 노이즈를 감소시키고, 계통 재구성의 정확도를 향상시킨다. 연구는 또한 자동화된 방법이 인간 전문가의 인도어 판단을 대체하거나 보완할 수 있음을 시사한다.
한계점으로는 레벤슈타인 거리 자체가 음운 변화를 완전히 반영하지 못하고, 차용어와 동형이의 구분이 어려운 점을 들었다. 이를 보완하기 위해 향후 음운 규칙 기반 전처리나 의미론적 임베딩을 결합한 하이브리드 모델을 제안한다. 전반적으로 이 논문은 언어학적 거리 측정과 단어 안정성 평가에 있어 자동화와 정량화를 동시에 달성한 중요한 연구이며, 대규모 다언어 데이터베이스 구축과 언어 보존 정책 수립에 실질적인 도구가 될 수 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기