고차원 희소 DAG 추정의 새로운 패널티 방법
초록
본 논문은 변수의 자연 순서가 주어졌을 때, 직접 인접행렬을 추정하는 penalized likelihood 프레임워크를 제안한다. lasso와 adaptive lasso 두 가지 패널티를 적용하고, 고차원 상황에서도 효율적인 알고리즘을 설계하였다. 이론적으로 adaptive lasso가 완화된 정규성 가정 하에 변수 선택 일관성을 보장함을 증명하고, 시뮬레이션 및 실제 데이터에서 기존 방법보다 우수한 성능을 확인하였다.
상세 분석
이 연구는 DAG(Directed Acyclic Graph) 추정 문제를 “인접행렬 직접 추정”이라는 관점에서 재구성한다는 점에서 혁신적이다. 전통적인 구조 학습은 조건부 독립 검정이나 점수 기반 탐색을 사용해 NP‑hard한 조합 최적화 문제에 직면한다. 그러나 변수에 자연스러운 순서(예: 시간 흐름, 유전자 발현 단계)가 존재한다면, 사이클이 발생하지 않도록 방향을 미리 정할 수 있다. 저자들은 이 전제를 이용해 각 노드 i에 대해 i보다 앞선 노드들의 선형 회귀 모델을 설정하고, 회귀계수 행렬을 바로 DAG의 인접행렬로 해석한다.
penalized likelihood는 로그우도에 l1(라쏘) 혹은 가중치가 부여된 l1(적응 라쏘) 패널티를 더하는 형태이며, 이는 고차원( p≫n ) 상황에서도 희소성을 강제한다. 라쏘는 전통적으로 변수 선택 일관성을 보장하려면 강한 irrepresentable condition과 같은 엄격한 가정을 필요로 한다. 반면 적응 라쏘는 초기 추정값(예: OLS 혹은 라쏘)으로부터 가중치를 부여해 큰 계수는 작은 패널티를, 작은 계수는 큰 패널티를 받게 함으로써, “oracle property”에 근접한다. 논문은 이론적 증명을 통해 적응 라쏘가 변수 수 p가 샘플 수 n보다 빠르게 증가하더라도, 적절한 페널티 파라미터 λ_n이 선택되면 true DAG를 일관적으로 복원한다는 결과를 제시한다.
알고리즘 측면에서는 좌표 하강법(coordinate descent) 기반의 경량 구현을 제안한다. 각 노드별 회귀는 독립적으로 수행될 수 있어 병렬화가 용이하고, 전체 인접행렬 업데이트는 O(p^2) 연산으로 제한된다. 또한, 순서가 주어졌다는 전제 덕분에 사이클 검증 절차가 불필요해 계산 복잡도가 크게 감소한다.
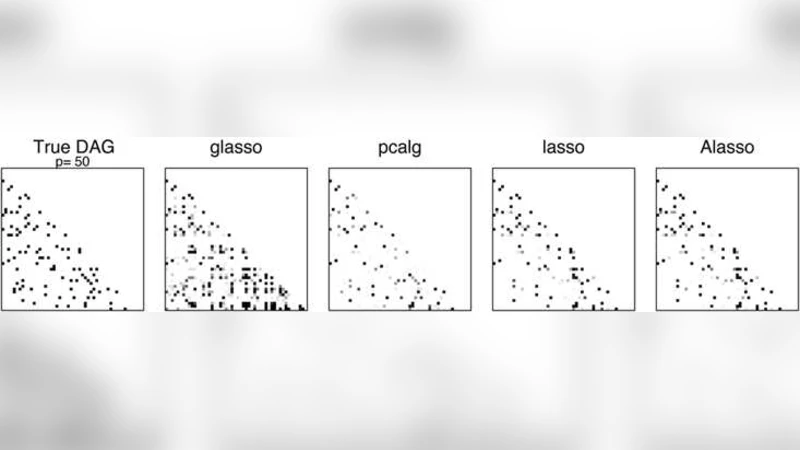
실험에서는 다양한 시뮬레이션 시나리오(희소성 수준, 신호‑대‑노이즈 비, 샘플 크기)와 실제 유전자 발현 데이터, 금융 시계열 데이터를 사용해 성능을 평가한다. 결과는 적응 라쏘가 F‑score, 구조 Hamming distance 등에서 기존 PC‑algorithm, GES, 그리고 순수 라쏘 기반 방법보다 우수함을 보여준다. 특히, 노이즈가 큰 상황에서도 적응 라쏘는 거짓 양성률을 억제하면서 중요한 에지들을 정확히 복원한다.
이 논문은 “자연 순서가 존재하는 고차원 DAG 추정”이라는 구체적 상황에 맞는 통계적·계산적 프레임워크를 제공함으로써, 복잡계 과학·생물정보학·경제학 등에서 인과 구조를 탐색하려는 연구자들에게 실용적인 도구와 이론적 보장을 동시에 제공한다.
댓글 및 학술 토론
Loading comments...
의견 남기기