쌍별 확률 모델의 통계 물리학적 접근
초록
본 논문은 신경계 데이터에 적용되는 쌍별 확률 모델을 통계 물리학 도구로 분석한다. 평균과 쌍별 상관관계만으로 파라미터를 추정하는 다양한 근사 방법의 정확도를 시뮬레이션된 피질 네트워크 데이터를 이용해 평가하고, 시간 구간(bin)의 크기가 모델 품질에 미치는 영향을 조사한다. finer한 시간 구간이 모델 적합도를 향상시킴을 확인한다.
상세 분석
이 연구는 생물학적 시스템, 특히 대규모 신경 집단의 상태 분포를 기술하기 위해 ‘쌍별 모델(pairwise model)’을 선택한 이유와 그 한계를 물리학적 관점에서 재조명한다. 쌍별 모델은 전체 시스템의 확률을 이진 스핀 변수들의 평균(첫 번째 순간)과 두 변수 간 상관(두 번째 순간)만으로 근사한다는 점에서 데이터 요구량이 비교적 적다. 그러나 실제 신경 데이터는 시간에 따라 변동성이 크고, 스파이크 발생이 희소한 비연속적 이벤트이기 때문에, 어떻게 ‘시간 구간(bin)’을 정의하느냐가 모델 파라미터 추정과 검증에 결정적 영향을 미친다.
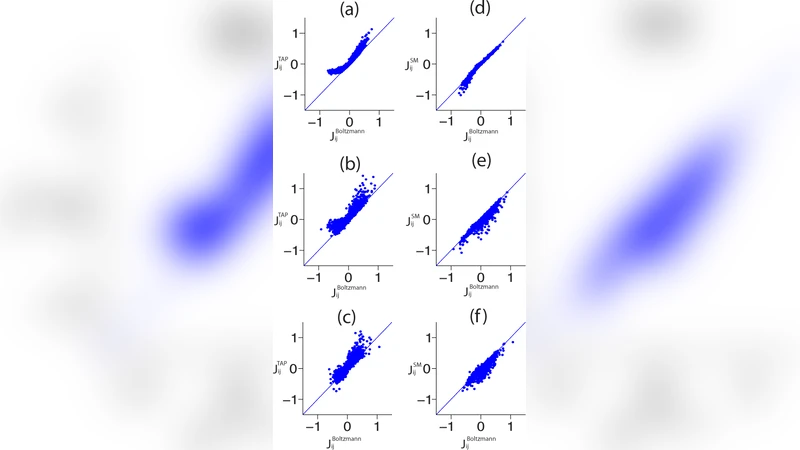
저자들은 먼저 기존에 사용되던 ‘역학적 평균장(Mean‑Field)’, ‘고차원 고전적 근사(Thouless‑Anderson‑Palmer, TAP)’, 그리고 ‘Pseudo‑likelihood’ 같은 추정 기법들을 정리하고, 각각이 가정하는 통계적 전제와 계산 복잡도를 비교한다. 특히, 평균장 근사는 상관이 약한(weakly correlated) 시스템에 적합하지만, 신경계처럼 강한 상호작용이 존재할 경우 편향이 크게 나타난다. TAP 식은 2차 상호작용까지 포함해 보다 정확한 근사를 제공하지만, 고차원 네트워크에서는 수렴 문제가 발생한다. Pseudo‑likelihood는 전체 가능도 대신 각 변수의 조건부 가능도를 최대화함으로써 계산량을 크게 줄이면서도 비교적 안정적인 추정치를 제공한다는 장점이 있다.
시뮬레이션에서는 실제 피질 네트워크를 모사한 스파이킹 뉴런 모델을 사용해 다양한 bin 크기(1 ms, 5 ms, 20 ms 등)를 적용하였다. 각 bin에 대해 평균 스파이크 확률과 쌍별 상관을 계산하고, 위의 세 가지 추정 방법으로 쌍별 모델 파라미터(J_ij, h_i)를 복원한다. 복원된 파라미터와 원래 시뮬레이션 파라미터 사이의 차이를 ‘Kullback‑Leibler divergence’와 ‘log‑likelihood 차이’로 정량화하였다. 결과는 bin이 작을수록(즉, 시간 해상도가 높을수록) 복원 정확도가 현저히 향상됨을 보여준다. 이는 작은 bin이 스파이크 이벤트를 더 정확히 포착해 실제 상관 구조를 보존하기 때문이다. 반면, 큰 bin은 여러 스파이크가 하나의 이진 상태로 합쳐지면서 정보 손실이 발생하고, 특히 높은 발화율을 가진 뉴런들 사이의 비선형 상호작용을 과소평가한다.
또한, 저자들은 기존 논문에서 제시된 ‘quality measure’(예: ‘pairwise model error’와 ‘entropy difference’)를 새로운 수식 전개를 통해 보다 직관적으로 유도한다. 이 과정에서 ‘cumulant expansion’과 ‘diagram적 전개’를 활용해 근사식의 오차 항을 명시적으로 구분함으로써, 어떤 상황에서 특정 근사가 과소/과대 추정되는지를 이론적으로 설명한다. 특히, 평균장 근사는 1차와 2차 누적량만 고려하므로, 고차 누적량이 무시될 수 없는 경우(강한 상관, 비선형 다중 상호작용)에는 오류가 급격히 증가한다는 점을 수식적으로 증명한다.
전반적으로 이 논문은 (1) 시간 구간 선택이 쌍별 모델의 적합도와 파라미터 추정 정확도에 미치는 정량적 영향을 실험적으로 입증하고, (2) 다양한 근사 추정 방법의 이론적 한계를 명확히 구분하며, (3) 모델 품질을 평가하는 새로운 수학적 도구를 제공한다는 점에서 통계 물리학과 신경 과학 사이의 교차 연구에 중요한 기여를 한다.
댓글 및 학술 토론
Loading comments...
의견 남기기