저자 공동인용 분석을 위한 정보이론 기반 유사도 측정과 클러스터링
안내: 본 포스트의 한글 요약 및 분석 리포트는 AI 기술을 통해 자동 생성되었습니다. 정보의 정확성을 위해 하단의 [원본 논문 뷰어] 또는 ArXiv 원문을 반드시 참조하시기 바랍니다.
초록
본 논문은 저자 공동인용 분석(ACA)에서 피어슨 상관계수와 살턴 코사인 유사도의 차이를 검토하고, 로그 변환을 이용한 정보계산법을 적용한다. 정보이론적 비파라메트릭 접근으로 문헌을 정확히 클러스터링하고, 클러스터 간 차이를 비트 단위의 정보량으로 표현한다. 제시된 알고리즘을 기존 ACA 데이터에 적용해 실험 결과를 제시한다.
상세 분석
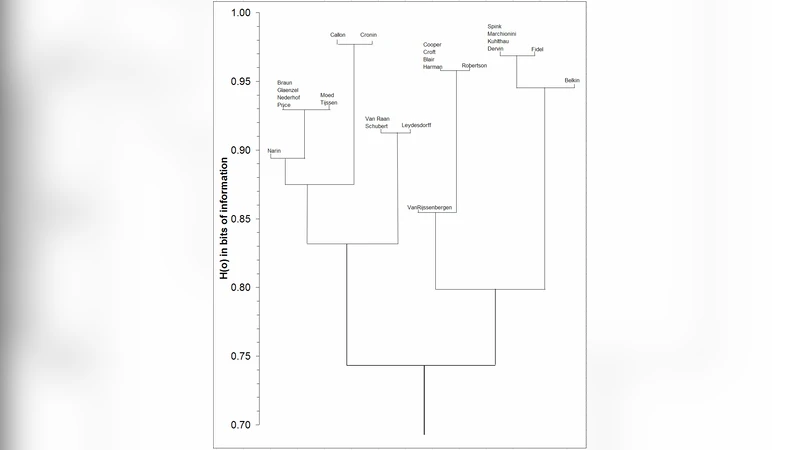
저자 공동인용 분석은 연구자 간 지식 흐름을 파악하는 핵심 도구이며, 유사도 측정 방법에 따라 군집 구조가 크게 달라진다. 전통적으로 피어슨 상관계수(r)는 두 저자 간 인용 빈도의 선형 관계를 평가하지만, 데이터 행렬에 다수의 0값이 포함될 경우 r값이 과도하게 감소하거나 왜곡되는 문제가 있다. 반면 살턴 코사인(·)은 벡터의 방향성만을 고려해 0값에 민감하지 않아 희소 행렬에 강건하다. 그러나 코사인은 절대적인 빈도 차이를 무시하므로, 인용 횟수가 현저히 다른 저자 쌍을 동일하게 평가할 위험이 있다.
이러한 한계를 보완하기 위해 논문은 로그 변환을 도입한다. 로그 변환은 빈도 스케일을 압축해 큰 차이를 완화하고, 동시에 정보이론적 엔트로피 계산에 필수적인 확률 분포를 생성한다. 변환 후 피어슨 상관계수를 적용하면, 0값은 −∞가 아닌 작은 값으로 처리되어 통계적 안정성을 확보한다.
핵심은 정보계산법(information calculus)이다. 저자-문서 행렬을 확률분포 P(i,j)로 정규화한 뒤, 각 행·열의 마진 분포 P(i·), P(·j)를 구한다. 이후 상호정보량 I(i;j)=log₂
댓글 및 학술 토론
Loading comments...
의견 남기기