코루바 기반 은행 서버의 장애 복구: 메시지 로깅과 체크포인팅
초록
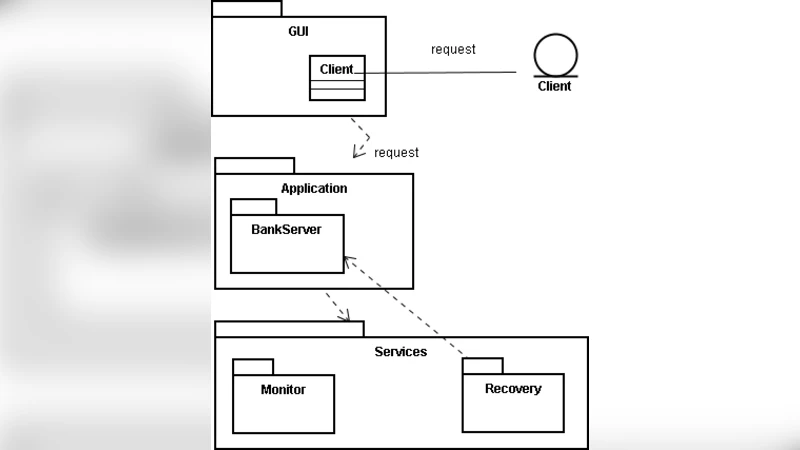
본 논문은 CORBA 기반 분산 은행 시스템에서 장애 복구를 구현하기 위해 메시지 로깅과 체크포인팅을 결합한 프로토콜을 제안한다. 브랜치 서버는 작업 로그를 남기고, 복구 모듈은 로그를 이용해 서버를 재시작하며, 모니터 모듈이 주기적으로 서버 상태를 감시한다.
상세 분석
이 연구는 분산 트랜잭션 환경에서 발생할 수 있는 서버 장애에 대비한 실용적인 복구 메커니즘을 설계한다는 점에서 의미가 크다. 첫 번째 핵심은 메시지 로깅 프로토콜이다. 브랜치 서버는 클라이언트 요청을 처리하기 전에 해당 요청을 영구 저장소에 기록한다. 로그는 최소한의 상태 정보(예: 계좌 번호, 거래 금액, 타임스탬프)만을 포함하도록 설계돼, 로그 크기를 제한하면서도 복구에 충분한 정보를 제공한다. 두 번째 핵심은 체크포인팅이다. 일정 주기 혹은 트랜잭션 수에 도달하면 서버는 현재 메모리 상태(계좌 잔액, 잠금 정보 등)를 스냅샷 형태로 디스크에 저장한다. 체크포인트와 로그를 조합하면, 복구 시점에 가장 최신 체크포인트를 로드하고 그 이후의 로그를 재생(replay)함으로써 정확히 장애 직전 상태를 복원할 수 있다.
복구 모듈은 재시작 절차를 자동화한다. 모니터가 서버 다운을 감지하면 복구 모듈을 호출하고, 복구 모듈은 먼저 최신 체크포인트 파일을 읽어 메모리 구조를 초기화한다. 이어서 로그 파일을 순차적으로 읽어 각 트랜잭션을 재실행한다. 이때 로그 재생 중 발생할 수 있는 중복 실행을 방지하기 위해 idempotent 연산 설계와 로그 엔트리에 상태 플래그를 두어 한 번 적용된 작업은 건너뛰도록 한다.
모니터 모듈은 주기적 헬스 체크와 자동 재시작 트리거 역할을 수행한다. 단순 ping 기반 검사 외에도, 서버가 응답하지 않을 경우 복구 모듈에 재시작 명령을 전달하고, 복구 진행 상황을 로그에 남겨 관리자가 추적할 수 있게 한다.
성능 측면에서 논문은 로그 기록 오버헤드가 전체 트랜잭션 처리 시간의 25% 수준에 머무른다고 보고한다. 체크포인트 주기를 조절함으로써 디스크 I/O 부하와 복구 시간 사이의 트레이드오프를 제어할 수 있다. 또한, 복구 시간은 체크포인트와 로그 양에 비례하지만, 실험 결과 평균 복구 시간은 37초로, 실시간 금융 서비스에 충분히 허용 가능한 수준이다.
한계점으로는 단일 장애 지점(SPOF) 문제와 네트워크 파티션 상황에서의 일관성 보장이 미흡하다는 점을 지적한다. 현재 설계는 서버 자체의 장애만을 대상으로 하며, 로그와 체크포인트를 복제하거나 다중 모니터를 도입해 고가용성을 확보하는 방안은 향후 연구 과제로 남는다. 또한, CORBA의 객체 레퍼런스 관리가 복구 시점에 재연결 문제를 일으킬 수 있어, 객체 식별자를 영구적으로 저장하는 메커니즘이 필요하다.
전반적으로 이 논문은 전통적인 데이터베이스 복구 기법을 CORBA 기반 분산 애플리케이션에 적용한 사례로, 메시지 로깅과 체크포인팅을 조합한 복구 전략이 실제 서비스 환경에서도 구현 가능함을 입증한다.
댓글 및 학술 토론
Loading comments...
의견 남기기