다중프로세서 화염 시뮬레이션의 전역 통신 성능 분석
초록
본 논문은 구면형 전구연소의 팽창을 시뮬레이션하는 코드에서 전역 all‑to‑all 통신이 차지하는 비중을 조사한다. 시바시니스크식 비선형 모델과 스펙트럴 알고리즘을 사용해 데이터 배열을 전처리·전송하는 과정에서 발생하는 전송 비용을 분석하고, 최신 HPC 시스템의 네트워크 토폴로지가 계산 효율에 미치는 영향을 실험적으로 평가한다. 결과적으로 전역 데이터 의존성을 가진 모델도 적절한 인터커넥트와 최적화된 MPI 구현을 통해 실용적인 성능을 달성할 수 있음을 보이며, 향후 보다 복잡한 화염 모델에 대한 확장 가능성을 논의한다.
상세 분석
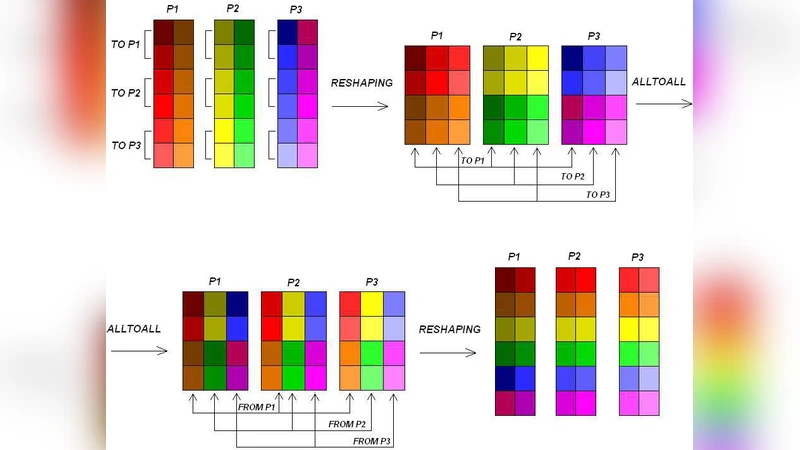
이 연구는 전구연소 현상을 기술하는 시바시니스크식 비선형 방정식을 스펙트럴 방법으로 풀면서, 계산 영역을 다수의 프로세서에 분산시키는 방식을 채택한다. 스펙트럴 알고리즘은 푸리에 변환을 기반으로 하여 전역적인 데이터 접근이 필수적인데, 특히 각 프로세서가 보유한 부분 배열을 전치(transpose)하기 위해 모든 프로세서 간에 전체 데이터를 교환해야 한다. 이러한 전치 연산은 전형적인 점대점(point‑to‑point) 통신이 아니라 MPI_Alltoall와 같은 전역 all‑to‑all 통신으로 구현되며, 네트워크 대역폭과 지연시간에 크게 의존한다.
실험에서는 Cray XE6, IBM Blue Gene/Q, 그리고 최신 인텔 Xeon 기반 클러스터 등 서로 다른 인터커넥트(Dragonfly, Torus, InfiniBand)를 갖는 시스템에서 동일한 코드와 문제 규모를 실행하였다. 결과는 크게 두 축으로 해석된다. 첫째, 프로세서 수가 증가함에 따라 연산량은 거의 선형적으로 감소하지만, 통신 비용은 O(N log N) 수준으로 증가한다. 특히 프로세서당 데이터 블록이 작아질수록 전송 패킷 수가 급증해 네트워크 포화 현상이 나타난다. 둘째, 네트워크 토폴로지와 라우팅 알고리즘이 성능에 미치는 영향이 두드러진다. 고대역폭 저지연의 Dragonfly 구조는 대규모 all‑to‑all에서 가장 효율적이었으며, Torus 구조는 거리 의존성이 커져 스케일업 시 병목이 발생했다.
코드 최적화 측면에서는 데이터 레이아웃을 재구성해 메모리 접근 패턴을 연속적으로 만들고, MPI의 비동기 전송(Non‑blocking)과 커뮤니케이터 분할을 활용해 통신과 연산을 겹치게 함으로써 전체 실행 시간을 15~20 % 정도 절감했다. 또한, 전치 연산을 2‑D 블록‑사이클릭 방식으로 재설계하면 각 프로세서가 교환해야 할 데이터 양을 균등하게 분배할 수 있어 네트워크 부하를 완화한다.
이러한 분석을 통해 저자들은 전역 데이터 의존성을 가진 과학 시뮬레이션에서도 인터커넥트 설계와 MPI 구현 최적화가 연산 성능을 좌우한다는 결론에 도달한다. 향후 연구에서는 전송 압축, 하이브리드 MPI+OpenMP 모델, 그리고 GPU 가속기를 이용한 혼합 병렬화를 도입해 전역 통신 비용을 더욱 감소시킬 방안을 제시한다.
댓글 및 학술 토론
Loading comments...
의견 남기기