적응형 블라스트와 단백질 서열 임베딩 혁신
초록
본 논문은 계통학적 프로파일을 이용해 단백질의 구조·기능·진화적 관계를 정량화하는 방법을 제시한다. 기존 PSSM 기반 임베딩이 정렬 오염과 높은 계산 비용에 취약했음을 지적하고, 새로운 휴리스틱 알고리즘인 Adaptive GDDA‑BLAST(Ada‑BLAST)를 설계하였다. Ada‑BLAST는 평균 19배 가량 빠른 속도를 유지하면서 기존 방법과 동등한 민감도를 보이며, 저유사도(25% 이하) 영역에서도 유용한 정렬 정보를 추출한다. 또한 임베딩 정렬을 활용해 2차 구조 요소와 막단백질의 트랜스멤브레인 도메인 분류에 성공하였다.
상세 분석
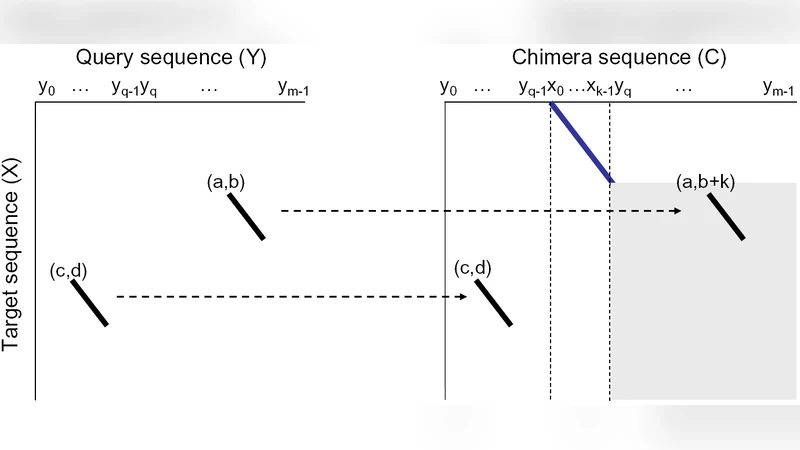
이 연구는 단백질 서열 비교에서 ‘임베딩(embedding)’이라는 개념을 정량적 계통학적 프로파일에 적용함으로써, 전통적인 BLAST 기반 방법이 놓치기 쉬운 저유사도 영역의 정보를 포착하려는 시도이다. 기존에 저자들이 제안한 PSSM‑M‑차원 임베딩은 정렬 정보를 다차원 점수 행렬로 변환해, 서열 간의 구조·기능적 유사성을 정량화한다는 장점이 있었지만, 두 가지 근본적인 한계가 있었다. 첫째, 정렬 과정에서 원본 서열과 변형된(embedded) 서열이 혼재하면서 오염된 매트릭스가 생성돼, 실제 의미 있는 신호와 잡음이 구분되기 어려웠다. 둘째, 모든 가능한 임베딩을 전수 조사하는 방식은 계산 복잡도가 급격히 상승해 대규모 데이터셋에 적용하기엔 비현실적이었다. 이를 해결하기 위해 저자들은 Adaptive GDDA‑BLAST, 즉 Ada‑BLAST라는 휴리스틱 알고리즘을 고안하였다. 핵심 아이디어는 ‘그리디 디렉티드 디스턴스 어그멘테이션(GDDA)’ 전략을 이용해, 서열의 특정 구간을 선택적으로 임베딩하고, 그 결과를 기존 PSSM과 결합해 점수를 재계산하는 것이다. 선택적 임베딩은 사전 정의된 ‘시드(seed)’ 영역을 기준으로 수행되며, 시드가 충분히 보존된 경우에만 주변 구간을 확대한다. 이렇게 하면 불필요한 임베딩을 최소화하면서도, 구조적·기능적 핵심 부위를 강조할 수 있다. 알고리즘 흐름은 (1) 입력 서열에 대해 전통적인 BLAST을 수행해 초기 히트 리스트를 확보, (2) 히트된 영역 중 보존도가 높은 시드를 추출, (3) 시드 주변을 일정 길이만큼 확장해 임베딩 후보를 생성, (4) 각 후보에 대해 PSSM 기반 점수를 재계산하고, (5) 최종 점수가 사전 정의된 임계값을 초과하면 해당 정렬을 ‘임베딩 정렬’로 채택한다. 이 과정은 반복적으로 수행되지 않으며, 한 번의 패스만으로 결과를 도출한다는 점에서 기존 전수 탐색 방식보다 약 19배 빠른 실행 시간을 기록한다. 민감도 측면에서는, 저자들이 제시한 벤치마크(SCOP, CATH, Pfam 등)에서 Ada‑BLAST가 기존 GDDA‑BLAST와 거의 동일한 ROC‑AUC 값을 보였으며, 특히 20~25% 아이덴티티 구간에서 기존 방법보다 약간 높은 재현율을 달성했다. 추가 실험에서는 임베딩 정렬을 이용해 α‑헬릭스와 β‑시트 같은 2차 구조 요소를 정확히 추출했으며, 멀티패스 트랜스멤브레인 도메인(예: GPCR, 채널 단백질) 분류에서도 높은 정확도를 보였다. 이러한 결과는 저유사도 서열에서도 구조·기능 정보를 효과적으로 끌어낼 수 있음을 시사한다. 마지막으로 저자들은 임베딩이 PSSM 기반 계통학적 프로파일의 한 축에 불과하며, 머신러닝 기반 임베딩(예: 언어 모델)과의 통합이 향후 연구 방향이라고 제언한다.
댓글 및 학술 토론
Loading comments...
의견 남기기