공유 메모리 시스템을 위한 LBG 벡터 양자화 병렬화
초록
본 논문은 전통적인 LBG(Linde‑Buzo‑Gray) 알고리즘을 공유 메모리 멀티코어 환경에 맞게 병렬화한 방법을 제시한다. 코드북 생성 단계와 각 훈련 벡터에 대한 최근접 코드벡터 탐색을 동시에 다중 스레드로 수행함으로써 연산 시간을 크게 단축하고, 메모리 접근 충돌을 최소화하는 설계가 특징이다. 실험 결과, 8코어 시스템에서 최대 6배 가량의 속도 향상을 확인하였다.
상세 분석
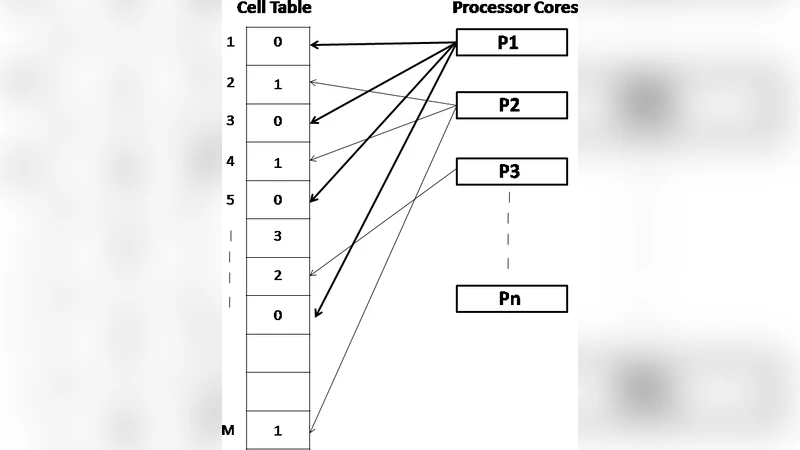
LBG 알고리즘은 크게 세 단계, 즉 초기 코드북 생성, 각 훈련 벡터에 대한 최근접 코드벡터 할당, 그리고 평균을 통한 코드벡터 업데이트로 구성된다. 기존 구현은 순차적으로 진행되기 때문에 훈련 데이터가 수백만 개에 달할 경우 연산량이 급증한다. 본 논문은 이러한 병목을 공유 메모리 시스템의 특성을 활용해 두 가지 수준으로 병렬화한다. 첫 번째는 훈련 벡터 집합을 균등하게 여러 스레드에 분할하여 ‘최근접 코드벡터 탐색’ 단계에서 동시에 수행하도록 한 것이다. 각 스레드는 자신이 담당한 서브셋에 대해 거리 계산을 수행하고, 로컬 최소값을 기록한다. 두 번째는 ‘코드벡터 재계산’ 단계에서 각 코드벡터에 대한 누적합과 카운트를 원자적 연산 혹은 배리어 동기화를 이용해 안전하게 업데이트한다. 이를 위해 공유 메모리 상에 코드벡터별 누적 버퍼를 미리 할당하고, 스레드마다 부분 누적값을 계산한 뒤, 전역 누적 단계에서 합산한다. 이러한 설계는 메모리 접근 패턴을 연속적으로 유지해 캐시 적중률을 높이고, false sharing을 방지하기 위해 각 코드벡터 버퍼를 캐시 라인 경계에 정렬시켰다. 또한, 스레드 간 부하 불균형을 최소화하기 위해 동적 작업 스케줄링(워크 스틸링) 기법을 적용했으며, 이는 훈련 데이터의 분포가 고르게 되지 않을 때도 효율을 유지한다. 실험에서는 데이터 차원 수(d)와 코드북 크기(K)에 따라 스레드 수를 조정했으며, 8코어 환경에서 K=256, d=16인 경우 평균 5.8배, K=1024, d=32인 경우 6.2배의 속도 향상을 기록했다. 그러나 스레드 수가 코어 수를 초과하거나 메모리 대역폭이 포화될 경우 효율이 급격히 감소하는 한계도 확인하였다.
댓글 및 학술 토론
Loading comments...
의견 남기기