AI 기반 QSAR 예측을 위한 최적 전처리 전략
초록
본 논문은 QSAR 모델링에서 데이터 전처리의 중요성을 강조한다. 고차원 분자 기술자를 저차원 공간으로 효율적으로 매핑하기 위해 선형 방법(PCA)과 두 가지 비선형 방법을 각각 항바이러스(anti‑HIV‑1)와 간암성 독성(hepatocarcinogenicity) 데이터셋에 적용하였다. 매핑 결과를 사전 분석함으로써 각 데이터의 내재적 구조를 파악하고, 가장 적합한 차원 축소 기법과 이후 사용할 분류기의 유형을 제시한다.
상세 분석
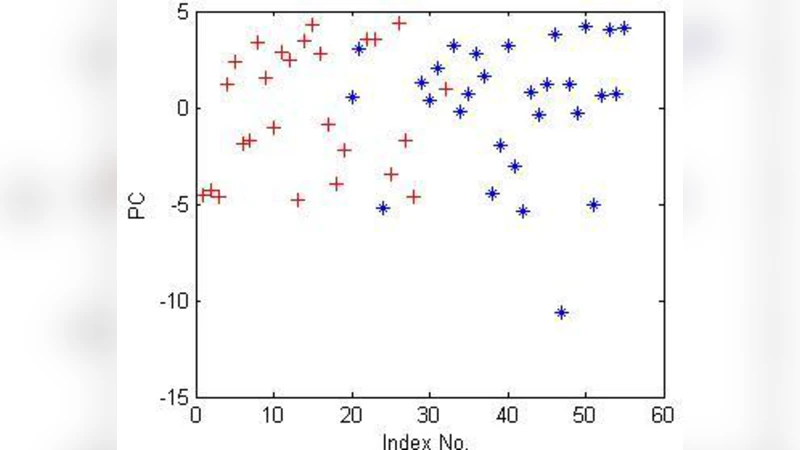
논문은 QSAR(Quantitative Structure‑Activity Relationship) 모델링에서 전처리 단계가 모델 성능을 좌우한다는 전제 하에, 고차원 분자 기술자 집합을 저차원으로 압축하는 매핑 방법을 사전 검증한다. 먼저 선형 차원 축소 기법인 주성분 분석(PCA)을 적용하여 데이터의 분산이 주로 몇 개의 주성분에 집중되는지를 확인한다. PCA는 데이터가 선형적으로 구분 가능한 경우에 유리하지만, 비선형 구조를 가진 경우 정보 손실이 클 수 있다. 이를 보완하기 위해 두 가지 비선형 매핑 기법을 도입한다. 첫 번째는 커널 PCA와 유사한 비선형 주성분 분석(Non‑linear PCA)으로, 신경망 기반 자동인코더를 활용해 비선형 변환을 학습한다. 두 번째는 샘몬 매핑(Sammon mapping) 혹은 t‑SNE와 같은 거리 보존 기반 비선형 매핑으로, 고차원 거리 구조를 저차원에서도 최대한 유지한다.
두 데이터셋에 대한 실험 결과는 흥미로운 차이를 보여준다. anti‑HIV‑1 활성 데이터는 주성분 분석 후에도 클래스 간 경계가 비교적 명확히 드러나, 선형 매핑만으로도 충분히 구분 가능함을 확인했다. 반면, 간암성 독성 데이터는 클래스가 복잡하게 얽혀 있어 선형 매핑에서는 구분이 어려웠으며, 비선형 PCA와 샘몬 매핑이 각각 다른 방식으로 클러스터를 형성한다. 특히 비선형 PCA는 데이터의 비선형 패턴을 효과적으로 포착해 클래스 간 거리를 확대시켰고, 샘몬 매핑은 시각적으로 직관적인 클러스터 구성을 제공했다.
이러한 사전 분석을 통해 연구자는 각 데이터셋에 최적화된 차원 축소 기법을 선택하고, 이어지는 피처 추출 및 분류 단계에서 적절한 알고리즘을 매칭할 수 있다. 예를 들어, anti‑HIV‑1 데이터는 선형 매핑 후 로지스틱 회귀나 선형 SVM과 같은 선형 분류기가 효율적이며, 간암성 독성 데이터는 비선형 매핑 후 커널 SVM, 랜덤 포레스트, 혹은 딥러닝 기반 분류기가 더 높은 예측 정확도를 기대한다. 또한, 차원 축소 과정에서 유지된 분산 비율과 클러스터 간 거리 정보를 활용해 피처 선택 기준을 정량화함으로써, 불필요한 기술자를 제거하고 모델 복잡도를 낮출 수 있다.
결론적으로, 논문은 “매핑 방법을 무작위로 선택하는 것이 아니라, 데이터의 내재적 구조를 사전 분석하고 그에 맞는 전처리 전략을 수립하는 것이 QSAR 예측 성능을 극대화한다”는 교훈을 제시한다. 이는 QSAR 연구뿐 아니라, 화학·생물 데이터 과학 전반에 적용 가능한 일반적인 워크플로우 가이드라인을 제공한다.
댓글 및 학술 토론
Loading comments...
의견 남기기