서비스 오케스트레이션 최적화와 Circulate 아키텍처
초록
본 논문은 중앙 집중형 오케스트레이션이 데이터 양과 서비스 수 증가에 따라 병목 현상을 일으키는 문제를 해결하고자, 서비스 간 직접 데이터 교환을 허용하는 Circulate 아키텍처를 제안한다. WS‑Circulate 구현을 기반으로 시퀀스, 팬‑인·팬‑아웃 등 전형적인 워크플로 패턴을 실험했으며, 통신 오버헤드 감소로 모든 패턴에서 2‑4배, 전체 Montage 워크플로에서는 8배 이상의 성능 향상을 확인하였다.
상세 분석
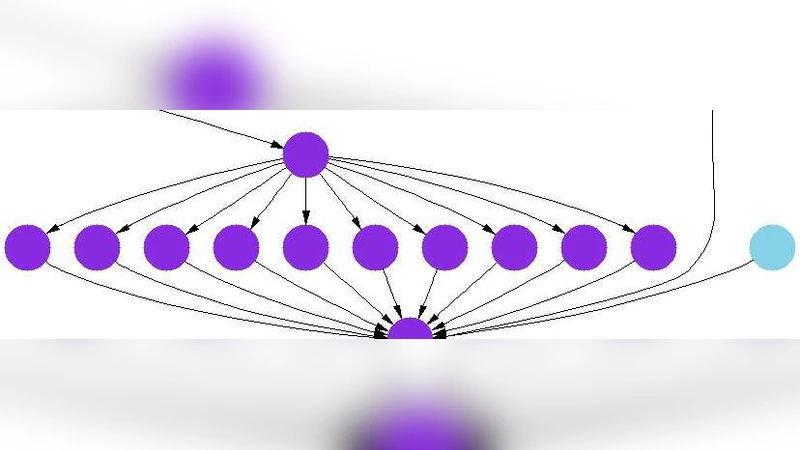
Circulate 아키텍처는 기존 중앙 엔진의 강점인 견고함과 관리 용이성을 유지하면서, 데이터 흐름을 서비스 간 피어 투 피어 방식으로 전환한다는 점에서 혁신적이다. 전통적인 중앙 오케스트레이션 모델에서는 모든 입력·출력 데이터가 중앙 엔진을 통과하므로, 특히 대용량 이미지나 과학 데이터와 같이 I/O가 지배적인 워크플로에서 네트워크 대역폭과 엔진 처리 능력이 급격히 포화된다. Circulate는 ‘데이터 라우팅 레이어’를 도입해 서비스 호출 메타데이터만 중앙에 남기고, 실제 데이터는 서비스 인스턴스 간에 직접 전송한다. 이는 데이터 복제와 전송 횟수를 최소화하고, 엔진의 CPU·메모리 부하를 크게 낮춘다.
논문은 WS‑Circulate라는 Web 서비스 기반 구현을 제시한다. 여기서는 SOAP 헤더에 데이터 위치 정보를 삽입하고, 서비스가 데이터를 필요로 할 때 해당 위치(예: HTTP 파일 서버, 클라우드 스토리지)에서 직접 다운로드하도록 설계되었다. 이러한 설계는 기존 BPEL·WS‑BPEL 엔진과 호환되며, 기존 워크플로 정의를 크게 수정하지 않아도 적용 가능하도록 한다.
성능 평가에서는 Montage 과학 워크플로를 모델로 삼아, 시퀀스, 팬‑인, 팬‑아웃, 그리고 복합적인 엔드‑투‑엔드 패턴을 실험하였다. 실험 환경은 로컬 LAN, WAN, 그리고 클라우드 기반 가상 네트워크 등 다양한 네트워크 토폴로지를 포함했으며, 입력 데이터와 출력 데이터의 크기 비율을 변형하여 스케일링 효과를 검증했다. 결과는 데이터 전송량이 70‑90% 감소하고, 전체 실행 시간이 2‑4배 단축되는 것을 보여준다. 특히 복합 패턴에서는 데이터 이동이 여러 단계에 걸쳐 누적되기 때문에, Circulate를 적용했을 때 8배 이상의 가속을 기록하였다.
또한 논문은 잠재적 한계점도 논의한다. 직접 데이터 교환은 보안·인증 메커니즘을 별도로 구현해야 하며, 데이터 위치 관리가 복잡해질 수 있다. 이를 보완하기 위해 암호화된 전송 채널과 토큰 기반 접근 제어를 제안한다. 마지막으로, 서비스 간 직접 전송이 실패할 경우를 대비한 롤백·재시도 전략도 설계 필요성을 강조한다.
요약하면, Circulate는 중앙 집중형 오케스트레이션의 관리 편의성을 포기하지 않으면서, 데이터 중심 워크플로의 병목을 효과적으로 해소한다. 이는 특히 빅데이터 분석, 과학 시뮬레이션, 멀티미디어 처리 등 대규모 데이터 흐름이 핵심인 분야에 큰 파급 효과를 기대할 수 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기